![]() Vorsicht, wenn der Aufruf der robots.txt-Datei zu einem 500er-Fehler führt: Dann stoppt Google das Crawlen der Website. Auf lange Sicht drohen sogar gravierendere Folgen.
Vorsicht, wenn der Aufruf der robots.txt-Datei zu einem 500er-Fehler führt: Dann stoppt Google das Crawlen der Website. Auf lange Sicht drohen sogar gravierendere Folgen.
Google reagiert sensibel auf 500er-Fehler. Mit HTTP-Status-Codes aus der 500er-Gruppe werden Serverprobleme signalisiert. Treten solche Fehler beim Crawlen auf, kann Google das Crawlen verlangsamen, um den betreffenden Server nicht noch mehr zu belasten. Bestehen die Fehler über längere Zeit, kann das sogar zum Deinidexieren von Seiten führen.
Noch problematischer ist es, wenn der Aufruf der robots.txt-Datei zu einem 500er-Fehler führt. Dann stoppt Google das Crawlen der Website. Bleibt der Fehler länger bestehen, droht mit der Zeit ein allmähliches Deindexieren der Seiten:
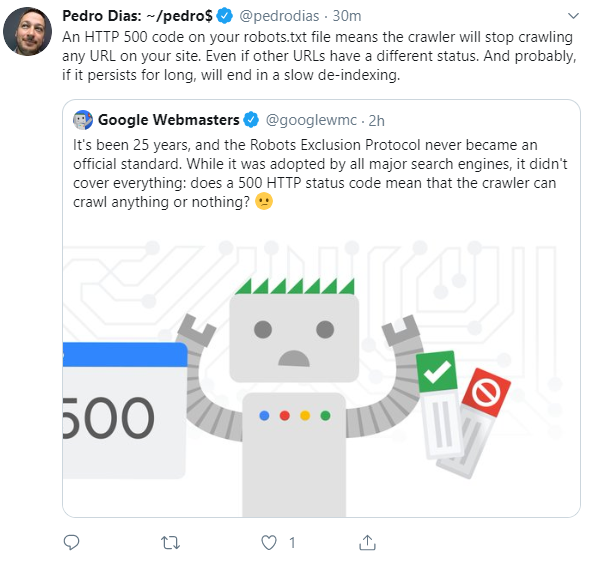
Daher sollte man regelmäßig überprüfen, ob die robots.txt verfügbar ist, sofern eine solche Datei angelegt wurde. Das kann entweder durch direkten Aufruf oder mit dem robots.txt-Tester in der Google Search Console erfolgen. Unproblematisch ist es, wenn es keine robots.txt gibt und wenn der Aufruf zu einem 404-Status für "nicht gefunden" führt.

