 Passage Retrieval ist eine Technik der Informationsrückgewinnung (Information Retrieval), die nur diejenigen Teile von Dokumenten (Passagen) liefert, die für ein spezielles Informationsbedürfnis relevant sind. Es handelt sich um einen Spezialfall und eine besondere Anwendung des Dokumenten-Retrievals, das wiederum die Rückgewinnung von relevanten Dokumenten mit Unterstützung duch Computertechnologie beschreibt.
Passage Retrieval ist eine Technik der Informationsrückgewinnung (Information Retrieval), die nur diejenigen Teile von Dokumenten (Passagen) liefert, die für ein spezielles Informationsbedürfnis relevant sind. Es handelt sich um einen Spezialfall und eine besondere Anwendung des Dokumenten-Retrievals, das wiederum die Rückgewinnung von relevanten Dokumenten mit Unterstützung duch Computertechnologie beschreibt.
Die Dokumente aus einem Pool, dem Dokumentenkorpus, werden beim Passage Retrieval in kleinere Einheiten, die Passagen, zerlegt. Passage Retrieval bedient sich unterschiedlicher Verfahren, mit denen die Relevanz der Passagen bestimmt und das Ranking für die zurückgewonnenen Passagen festgelegt werden.
Unterteilungsmöglichkeiten von Dokumenten in Passagen
Um Passagen identifizieren zu können, die eine ausreichende Relevanz zum Informationsbedürfnis des Anwenders besitzen, muss ein Dokument zunächst einmal in mehrere Einheiten unterteilt werden. Je nach Suchanfrage und Kontext kann die Größe von Passagen auch ein komplettes Dokument umfassen, wenn es durchgehend als relevant erachtet wird. Die Unterteilung kann nach rein strukturellen Aspekten der Dokumente geschehen, also beispielswiese anhand von Kapiteln, Überschriften, Absätzen und Sätzen in einem Text, sie kann sich aber auch an semantischen Aspekten orientieren. Dabei wird versucht, thematisch zusammenhängende Bereiche zu identifizieren.
Zur Bildung logischer Einheiten eines Dokuments kann beispielsweise die folgende Zuordnung dienen:
- Satz: einzelne Idee
- Absatz: einzelner Oberbegriff
- Kapitel: Kernthema
Sollen semantische Einheiten gebildet werden, können spezielle Algorithmen zum Einsatz kommen, die aufgrund der jeweils verwendeten Worte und Worthäufigkeiten Themenwechsel erkennen können. Hierzu gibt beispielsweise Ansätze, die auf der Erweiterung des TextTiling-Algorithmus' basieren.
Die Kernprobleme bei der Unterteilung von Dokumenten in Passagen sind die folgenden:
- Es gibt keine allgemein richtige Unterteilung. Vielmehr hängt die passsende Unterteilung von der jeweiligen Suchanfrage und dem herrschenden Kontext ab.
- Eine zu feine Unterteilung kann die Relevanz der einzelnen Passagen zu sehr reduzieren, eine zu grobe Unterteilung vermindert die Vorteile, die durch die Unterteilung erzielt werden sollen.
Eine Unterscheidung in der Weise, wie die Aufteilung von Dokumenten erfolgt, ergibt sich durch die Wahl zwischen fixer und variabler Länge der Passagen. Beiden Ansätzen, sowohl der fixen als auch der variablen Längeneinteilung von Passagen, ist gemein, dass die Startpunkte, an denen die Passagen beginnen, zunächst einmal beliebig sind. Der initiale Startpunkt wird nach der Eingabe der Suchanfrage bestimmt. Bei einer fest vorgegeben Länge der Passagen, also zum Beispiel 400 Wörtern pro Passage, können dann vom Anfang bis zum Ende des Dokumetes Passagen jeweils gleicher Länge gebildet werden. Ist die Schrittweite zwischen zwei aufeinander folgenden Startpunkten dabei kleiner als die vorgegebene Länge der Passagen, übergeben sich Überlappungen. Die Methode des schrittweisen Voranschreitens im Text wird auch als Sliding Window-Ansatz bezeichnet.
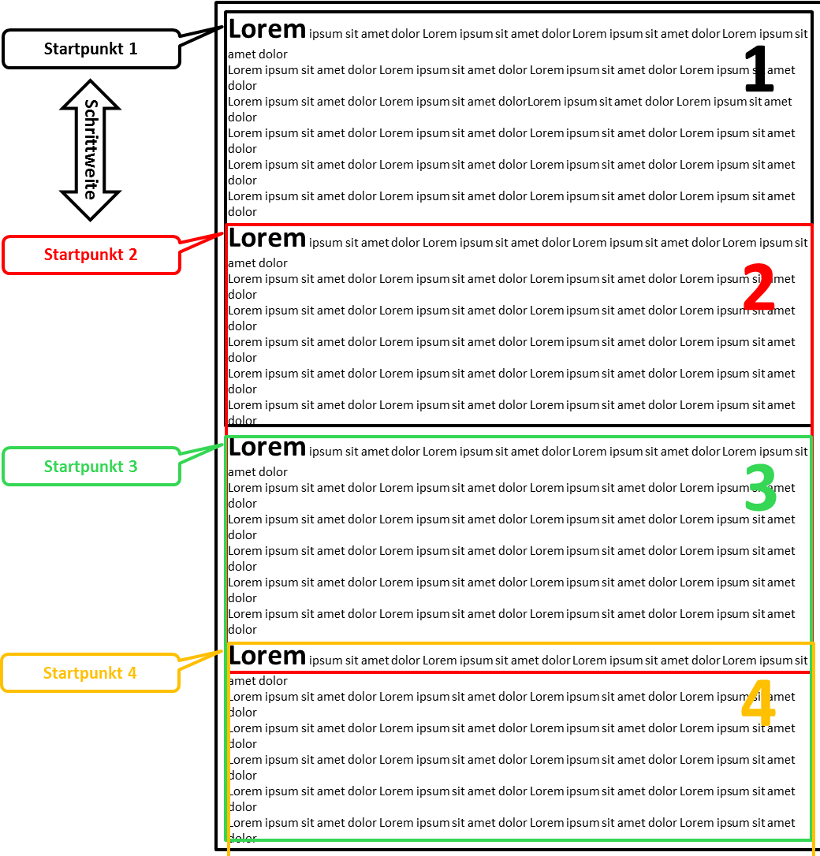
Bei variabler Länge der Passagen erhöht sich die Menge der potentiellen Passagen weiter. Daddurch kann es hier zu einem hohen Rechenaufwand kommen.
Modelle des Passage Retrievals
Es gibt zahlreiche Ansätze, mit denen die Relevanz von Passagen in Bezug auf bestimmte Suchphrasen bestimmt werden kann. Manche davon bedienen sich bestimmter Sprachmodelle, andere nutzen statistische Verfahren. Auch Maschinenlernen kann zum Einsatz kommen, um Ergebnisse von Suche zu Suche zu verbessern. Einige der Modelle werden im Folgenden dargestellt.
TFIDF
Ein klassischer Ansatz zur Relevanzbestimmung ist der des TFIDF, was für "Term Frequency Inverse Document Frequency" steht. Dahinter verbirgt sich die folgende Annahme: Wenn ein Term innerhalb eines Dokuments häufig vorkommt, also eine hohe Termfrequenz besitzt, auf der anderen Seite aber im gesamten Dokumentenkorpus selten anzutreffen ist (Inverse Dokumentenhäufigkeit), so ist das betreffende Dokument für diesen Termn relevant.
Im Passage Retrieval werden jede Passage und jede Suchanfrage als Vektor im Gesamttextraum betrachtet. Die Relevanz einer Passage für eine bestimmnte Suchanfrage ergibt sich aus der Multiplikation des Vektors, der die Suchanfrage repräsentiert, mit dem Vektor der Passage. Dabei entspricht das Gewicht jeder Dimension der beiden Vektoren den Produkt aus Termfrequenz (TF) und inverser Dokumentenfrequenz (IDF).
TFIDF lässt sich auch diese Formel darstellen:

Query Likelihood Language Model und Relevance Modelling Approach
Sowohl das Query Likelihood Model als auch der Relevance Modelling Approach bedienen sich statistischer Methoden zur Relevanzbestimmung von Passagen. Dabei wird, ausgehend von bestimmten Sprachmodellen, eine angenommene Wahrscheinlichkeitsverteilung des Vokabulars in den Dokumenten und Passagen vorausgesetzt. Für jede Suchanfrage wird dann bestimmt, mit welcher Wahrscheinlichkeit sie zu den einzelnen Dokumenten bzw. Passagen passt.
Bootstrap Vector Machine
Ziel dieses Ansatzes ist es, durch Maschinenlernen immer besser relevante von nicht relevanten Passagen unterscheiden zu können. Es wird zunächst mit positiven und negativen Beispielen gearbeitet. Diese Beispiele werden durch Datenpunkte im Mehrdimensionalen Vektorraum repräsentiert. Mit Hilfe einer Diskriminanzanalyse werden dann relevante von nicht relevanten Dokumenten unterschieden.
Ein Nachteil dieses Ansatzes ist, dass er sehr rechenintensiv sein kann. Außerdem muss bei den Trainingsbeispielen auf ein ausgewogenes Verhältnis zwischen relevanten und nicht relevanten Beispielen geachtet werden, da ansonsten die Lern- und Erkennungsrate leiden können.
Mixture of Language Model
Beim Mixture of Language-Modell werden Informationen aus einer Passage und dem sie umgebenden Text genutzt. Dabei gilt folgende Annahme: Jedes Wort in einer Passage entsteht durch eine Mischung aus drei multinominalen Sprachmodellen, nämlich dem Korpusmodell, dem Modell des Dokuments und dem Modell der Passage selbst. Die Gewichte dieser Faktoren können unterschiedlich gesetzt sein. Als Formel ausgedrückt ergibt sich:

Alle drei Sprachmodelle werden mit Hilfe der Maximum-Likelihood-Methode berechnet. Anschließend wird die Divergenz der Sprachmodelle der Suchanfrage und des berechneten, gemischten Sprachmodells durch Anwendung der negativen Kullback-Leibler-Divergenz bestimmt. Auf diese Weise erhält man den Relevanz-Score für die einzelnen Passagen.
Query Word Density
Im Gegensatz zu den anderen hier dargestellten Ansätzen zur Relevanzbestimmung von Passagen wendet das Query Word Density Model eine variable Passagenlänge an. Jedes Wort innerhalb eines zu prüfenden Dokuments wird gewertet. Die Gewichte der Suchbegriffe aus der Suchanfrage werden linear skaliert, und zwar so lange, bis jeder Begriff einen ganzzahligen Wert wi besitzt. Anschließend werden jeweils wi Worte jeweils rechts und links des Suchbegriffs markiert. Sobald dies für jeden Suchbegriff durchgeführt wurde, wird jede auf diese Weise entstandene Wortgruppe, die größer als ein vorher festgelegter Schwellwert ist, als Passage zurückgeliefert.
Diese Passagen können dann anschließend beispielsweise mit Hilfe des Mixture of Language-Modells bewertet werden.
Vorteile des Passage Retrievals
Im Gegensatz zum klassischen Dokumentenretrieval bietet das Passage Retrieval den Vorteil, dass nur die relevantesten Passagen von Dokumenten zurückgeliefert werden. Dies entlastet den Anwender, der sich ansonsten gerade bei umfangreichen Dokumenten einer großen Informationsmenge gegenüber sieht. Es können kurze, relevante Passagen herausgelesen und erkannt werden, auch wenn sie sich zwischen weniger relevanten Passagen befinden.
Einzelne Passagen weisen in der Regel eine größere Ähnlichkeit mit Suchphrasen auf als ganze Dokumente. Dies kann zur Rückgewinnung zusätzlicher Passagen führen, was wiederum eine Verbesserung der Recall- und Precision-Raten bewirken kan, also einen höheren Anteil von relevanten Dokumenten im Suchergebnis.
Zudem kann es im Dokumenten-Retrieval bei umfangreichen Dokumenten dazu kommen, dass relevante Passagen nicht genügend zur Geltung kommen, wenn ein größerer Teil dieser Dokumente nicht oder nur wenig relevant ist. Dies kann im Passage Retireval vermieden werden.
Das Rückgewinnung von Dokumenten wird beim Passage Retrieval vereinfacht, weil in der Regel kürzere Texteinheiten einfacher zu finden sind als lange Texte. Ein Grund dafür ist, dass in langen Texten relevante Inhalte weiter voneinander entfernt liegen und somit übersehen werden können.
Schließlich kann beim Passage Retrieval das Problem vermieden werden, das sich aus dem Vergleich unterschiedlich langer Dokumente ergibt, das heißt, ein "Verwässern" durch Länge ist bei einheitlicher Länge der Passagen nicht mehr gegeben.
Nachteile des Passage Retrievals
Methoden zur Berechnung relevanter Passagen können sehr rechenintensiv sein und eignen sich daher unter Umständen nicht immer zum Echtzeiteinsatz (siehe zum Beispiel den Absatz über die Bootstrap Vector Machine).
Die Vielzahl der möglichen Aufgliederungen eines Dokuments in Passagen und die große Menge an Rechenmodellen zur Bestimmung der Relevanz und des Ranking von Passagen erfordern eine genaue Sachkenntnis, um die für den jeweiligen Einsatzzweck optimale Konfiguration zu erzielen.
Vergleiche zwischen klassischem Dokumenten-Retrieval und Passage-Retrieval
Untersuchungen haben gezeigt, dass das Passage-Retireval mit festen Längen der Passagen Effektivitätsgewinne gegenüber dem klassischen Dokumenten-Retrieval bringen kann. Die Verbesserungen bewegten sich in den Tests zwischen 8 und 37 Prozent. Noch besser schnitt das Passage-Retrieval mit variablen Längen ab. Dazu wurden beim Verarbeiten der Suchanfragen jeweils Passagen unterschiedlicher Länge gebildet und die jeweils am besten passenden Passagen ausgewählt. Dieser Gewinn an Effektivität musste jedoch mit einem erhöhten Rechenaufwand erkauft werden.
Fazit
Passage Retrieval ist ein vielversprechender Ansatz zur Rückgewinnung von relevanten Informationen in Form passender Textstellen bzw. Passagen. Im Vergleich zum herkömmlichen Information Retrieval können die Ergebnisse beim Passage Retrieval überzeugen. Allerdings steht dem ein erhöhter Rechenaufwand entgegen. Zudem erfordern die Auswahl der passenden Methoden und der Optimierung der Untergliederung von Dokumenten sowohl Sachverstand als auch Geduld.
Iim Rahmen dieses Beitrags lassen sich die Eigenschaften und die Einsatzmöglichkeiten des Passage Retrievals nur oberflächlich beschreiben. Jede einzelne Methode der Relevanzbestimmung oder der Unterteilung von Dokumenten würde einen eigenen Beitrag füllen. Dennoch lässt sich recht gut erkennen, was das Passage Retrieval auszeichnet und wie es genutzt werden kann.
In der Praxis wird das Passage Retrieval mit Sicherheit schon vielfach genutzt - etwa von den Suchmaschinen, um passende Descriptions in den Snippets der Suchergebnisse anzeigen zu können.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige

{extravote 1}















