Das neue Claude Opus zeigt bisher unerreichte Stärken im Bereich Agentic Search. Der Abstand zur Konkurrenz ist groß.
Die richtige Antwort auf einfache Fragen zu geben ist etwas, das vielen LLMs Probleme bereitet. Das unterscheidet sie von klassischen Suchmaschinen. Aufgrund der Funktionsweise von LLMs kommt es hier oft zu Fehlern und Halluzinationen.
Deshalb ist ein wichtiges Kriterium bei der Bewertung von LLMs der Anteil richtiger Antworten. Hier beweist das neue Flagschiff von Anthropic, Claude Opus 4.6, deutliche Stärken. Das Modell liegt bei der sogenannten Agentic Search deutlich vor den Wettbewerbern. Im BrowseComp Benchmark erreicht das Modell 84 Prozent. Auf Platz zwei folgt GPT-5.2 mit 77,9 Prozent. Im Vergleich zum Vorgänger Opus 4.5 (67,8 Prozent) ist das neue Spitzenmodell von Anthropic ebenfalls deutlich besser.
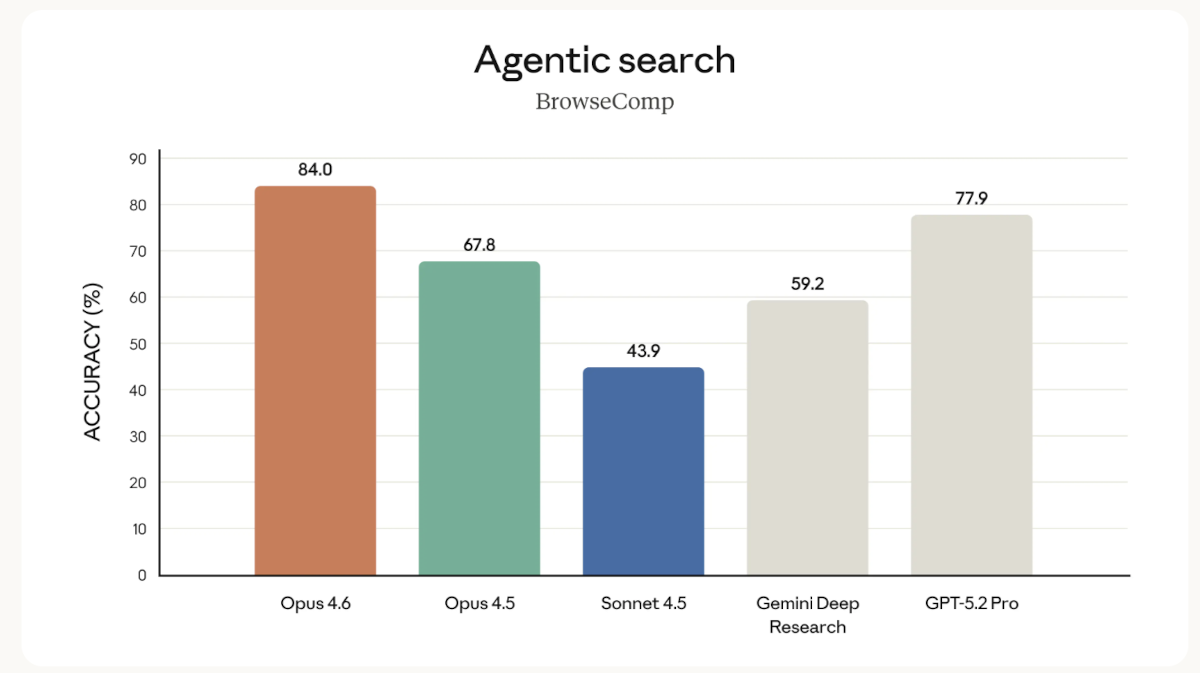
BrowseComp (kurz für „Browsing Competition“) ist ein von OpenAI veröffentlichter Benchmark, der speziell entwickelt wurde, um die Fähigkeit von KI-Agenten zu bewerten, schwer auffindbare Informationen im Internet zu lokalisieren.
SEO-Beratung: Wir sind Ihre Experten
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.

Christian Kunz
SEO Experte

David Wulf
SEO Experte

Sven Häwel
Offpage-Experte
Der Test besteht aus 1.266 Aufgaben, die so konzipiert sind, dass sie extrem schwierig zu lösen, aber einfach zu überprüfen sind. Die Fragen verlangen kurze, eindeutige Antworten, die nicht auf den ersten Ergebnisseiten von Suchmaschinen zu finden sind. Um erfolgreich zu sein, müssen die Agenten oft Dutzende oder Hunderte von Webseiten durchsuchen, Informationen strategisch verknüpfen und eine hohe Ausdauer bei der Recherche beweisen.
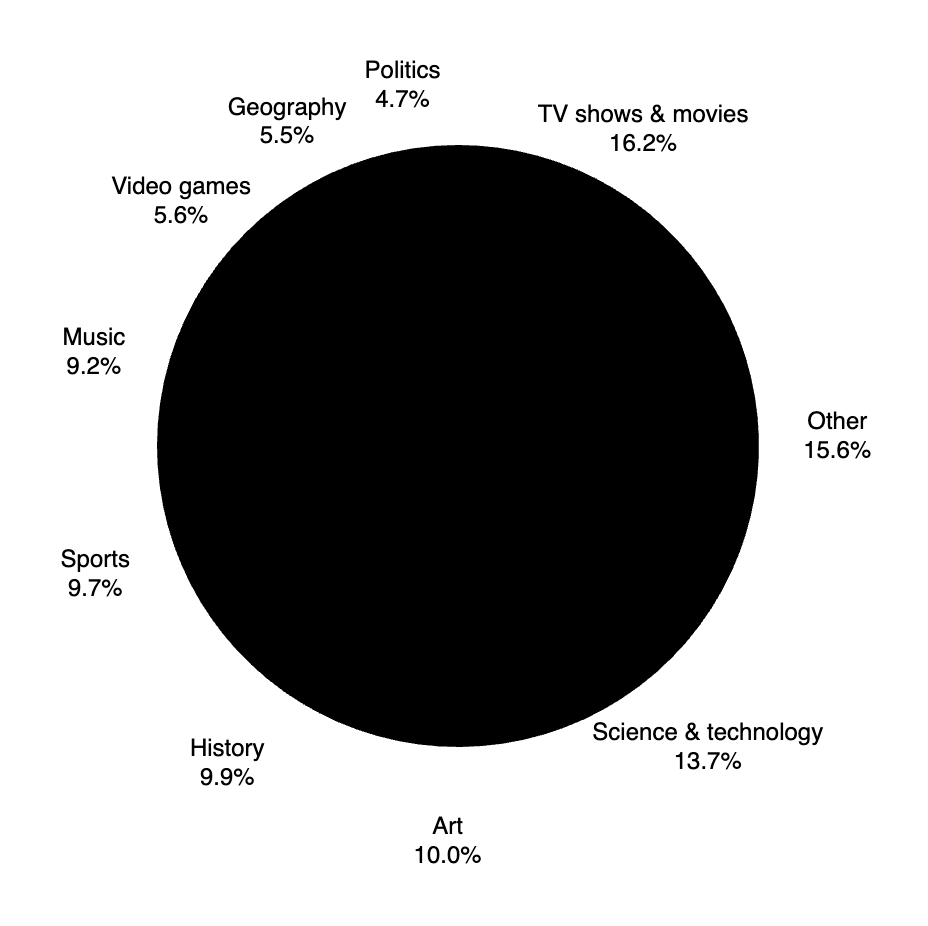
Die Zusammensetzung der Themen im BrowseComp Benchmark ist vielfältig und umfasst unter anderem Politik, TV-Programm, Musik, Videospiele und einige mehr.
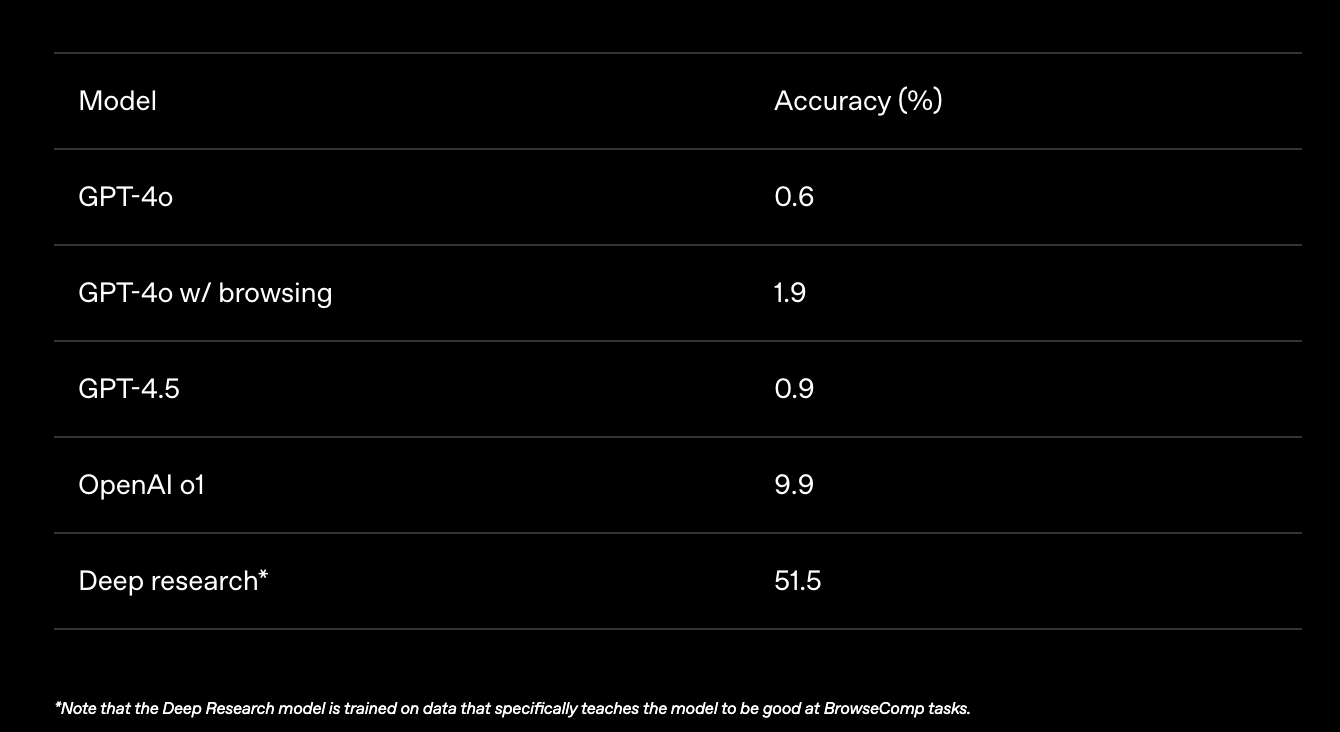
Wie schwierig es für LLMs ist, richtige Fragen auf einfache Antworten zu finden, zeigen die Ergebnisse einiger älterer OpenAI-Modelle. Selbst mit Deep Research liegt die Quote richtiger Antworten bei nur etwas über 50 Prozent:
Auch wenn Opus 4.6 die bisher beste Leistung bei der Beantwortung einfacher Suchanfragen liefert, bleibt eine gewisse Unsicherheit. Fehler können nach wie vor passieren. Deshalb ist es wichtig, den Antworten der KI nicht einfach zu vertrauen, sondern diese durch zusätzliche Recherchen abzusichern.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















