
Google AI Overviews und AI Mode: Diese Inhalte bieten gute Chancen auf Citations
Eine aktuelle Auswertung zeigt, dass Definitionen und Begriffserklärungen gute Chancen auf Citations in den Google KI-Features haben.

Das von Google vorgestellte OKF-Format ermöglich die Ablage und den Austausch von Wissen speziell für KI-Systeme.


Google Cloud hat das Open Knowledge Format (OKF) vorgestellt, eine offene Spezifikation dafür, wie Unternehmen Wissen für KI-Systeme ablegen und untereinander austauschen können Die Idee dahinter: Wissen liegt als Verzeichnis von Markdown-Dateien mit festen Konventionen vor, sodass ein KI-Agent die Dateien eines fremden Teams ohne Übersetzung weiterverwenden kann. Google greift damit die Idee des LLM Wiki von Andrej Karpathy auft, und gießt sie in ein einheitliches, herstellerunabhängiges Format.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Große Sprachmodelle scheitern oft am fehlenden Kontext. Ein Modell kann Code schreiben, Dokumente zusammenfassen oder einen Datensatz auswerten. Sobald aber das interne Wissen fehlt, etwa das Schema einer Tabelle, die Bedeutung einer Kennzahl oder der Ablauf bei einem Störfall, bleiben die Antworten vage oder sind falsch. Genau hier setzt das OKF an.
In den meisten Unternehmen steckt das Wissen, das ein KI-Modell braucht, in internen Quellen. Das Schema einer Tabelle steht im Datenkatalog, die Bedeutung einer Kennzahl im Wiki, die Logik eines Joins in den Köpfen weniger erfahrener Entwickler. Diese Informationen verteilen sich auf Systeme, die nicht miteinander reden: Metadaten-Kataloge mit eigener API, Wiki-Seiten und Shared Drives, Code-Kommentare und Notebook-Zellen.
Möchte ein Agent zum Beispiel die Zahl der wöchentlichen Nutzer aus einem Stream verschiedener Daten berechnen, muss er die Antwort aus all diesen Quellen zusammensuchen.
Statt einen weiteren Dienst zu bauen, schlägt Google mit OKF ein neues Format vor, das jeder ohne SDK erzeugen und ohne Integration lesen kann, das einen Umzug zwischen Systemen und Organisationen übersteht und neben dem Code in der Versionsverwaltung liegt. Dieselbe Datei dient dem Menschen zum Lesen und dem Agenten zum Auswerten, ganz ohne Übersetzungsschicht.
OKF v0.1 beschreibt Wissen als Verzeichnis von Markdown-Dateien. Ein Bündel aus OKF-Dokumenten ist gewöhnliches Markdown, in jedem Editor lesbar und auf GitHub darstellbar.

Ein Bundle ist ein Verzeichnis, dessen Dateien jeweils ein Konzept beschreiben: eine Tabelle, einen Datensatz, eine Kennzahl, ein Playbook, ein Runbook oder eine API. Ein Konzept entspricht einer Datei, und der Dateipfad ist die Identität des Konzepts. Ein Bundle Jedes Konzept-Dokument trägt oben einen kleinen YAML-Block für die strukturierten Felder und darunter einen Markdown-Text für alles Weitere:
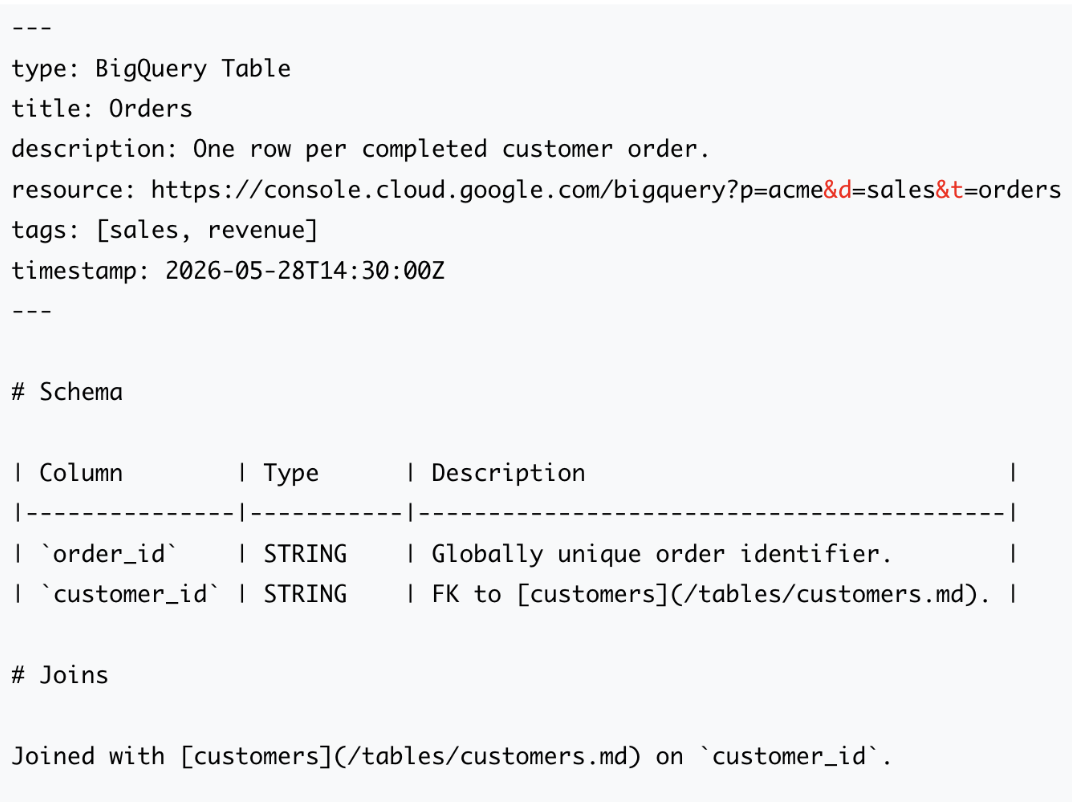
Die wenigen reservierten Felder im YAML-Block haben eine feste Bedeutung:
|
Feld |
Bedeutung |
|---|---|
|
type |
Einziges Pflichtfeld. Art des Konzepts, etwa „BigQuery Table“ oder „Metric“. |
|
title |
Anzeigename des Konzepts. |
|
description |
Kurzbeschreibung in einem Satz. |
|
resource |
Link auf die zugrunde liegende Ressource, zum Beispiel die Tabelle in der Konsole. |
|
tags |
Schlagwörter zur Einordnung, etwa [sales, revenue]. |
|
timestamp |
Zeitpunkt der letzten Änderung. |
Konzepte verweisen mit normalen Markdown-Links aufeinander. Aus dem Verzeichnis wird so ein Graph von Beziehungen. Zwei besondere Dateien helfen beim Navigieren: eine index.md gibt einen Überblick über die Inhalte eines Ordners, damit ein Agent sich schrittweise vorarbeiten kann; eine log.md hält die Änderungen chronologisch fest.
Der übliche Weg, ein Modell mit Dokumenten arbeiten zu lassen, heißt RAG (Retrieval Augmented Generation): Man lädt Dateien hoch, das Modell holt sich zur Frage passende Schnipsel und formuliert daraus eine Antwort. Das funktioniert, doch das Modell erschließt sich das Wissen bei jeder Frage neu. Es baut sich nichts auf. Eine Frage, die fünf Dokumente verbindet, zwingt das Modell jedes Mal dazu, die passenden Fragmente erneut zu suchen und zusammenzusetzen.
Das LLM Wiki dreht das um. Statt rohe Dokumente bei jeder Anfrage neu zu durchsuchen, baut und pflegt das Modell ein dauerhaftes Wiki: eine strukturierte, untereinander verlinkte Sammlung von Markdown-Dateien, die zwischen dem Menschen und den Quellen sitzt. Kommt eine neue Quelle hinzu, liest das Modell sie, zieht die Kernpunkte heraus und arbeitet sie in das bestehende Wiki ein. Es aktualisiert Einträge zu einzelnen Begriffen, schreibt Zusammenfassungen um und vermerkt, wo neue Angaben den alten widersprechen. Das Wissen wird einmal verdichtet und danach aktuell gehalten.
Der Unterschied zu RAG lässt sich kurz gegenüberstellen:
|
Klassisches RAG |
LLM Wiki | |
|---|---|---|
|
Vorgehen |
Holt zu jeder Frage passende Text-Schnipsel aus den Rohdokumenten. |
Pflegt ein dauerhaftes, verlinktes Wiki zwischen Frage und Rohquellen. |
|
Wissen |
Wird bei jeder Anfrage neu erschlossen. |
Wird einmal verdichtet und laufend aktuell gehalten. |
|
Querverweise |
Entstehen jedes Mal neu. |
Liegen bereits fest und werden gepflegt. |
|
Widersprüche |
Bleiben oft unbemerkt. |
Werden beim Einarbeiten markiert. |
|
Gut geeignet für |
Sehr große Datenmengen im Bereich von Millionen Token. |
Überschaubare, dichte Wissensbestände bis einige Hundert Seiten. |
Das OKF ist zunächst ein internes Format für Datenteams, kein Webstandard für die Google-Suche. Es lebt im eigenen Repo oder Data Warehouse und füttert die eigenen Agenten. Es wird nicht von GPTBot oder Googlebot eingelesen. Für die klassische Suchmaschinenoptimierung ändert OKF deshalb erst einmal wenig.
Wer als SEO für mehrere Kunden Inhalte produziert, kann Briefings, Keyword-Maps, Redaktionsrichtlinien und frühere Analysen in einem internen Bundle bündeln. Ein Agent beantwortet dann Fragen zu einem Kunden konsistent und greift auf denselben Wissensstand zurück, statt jede Vorgabe neu erklärt zu bekommen. Das ist zunächst ein Gewinn an Tempo in der eigenen Arbeit.
GEO belohnt dasselbe Prinzip, das hinter dem OKF steckt: Wissen maschinell lesbar, sauber strukturiert, mit Quellen belegt und aktuell halten.
Auf öffentlichen Websites hat dieses Denken bereits einen Verwandten: die Datei llms.txt. OKF und llms.txt teilen dieselbe Grundidee, Wissen für Maschinen aufzubereiten, setzen sie aber an verschiedenen Stellen um: llms.txt nach außen für fremde Crawler, OKF nach innen für die eigenen Agenten.
Nein. OKF beschreibt, wie Wissen intern für KI-Agenten abgelegt wird. Es liegt im Repo oder Data Warehouse, nicht als öffentliches Auszeichnungsformat im Quelltext einer Webseite.
Nicht direkt. Den Hebel für die generative Suche liefern strukturierte, quellenfeste Inhalte auf der öffentlichen Website, etwa über schema.org und klare Entitäten.
Das LLM Wiki ist die Idee: ein Modell pflegt ein dauerhaftes, verlinktes Wiki. Das OKF ist das standardisierte Format, das solche Wikis zwischen Teams und Werkzeugen austauschbar macht.


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
