
Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 Was Ihr beachten müsst, wenn Ihr das Crawlen und Indexieren Eurer Seite durch verschiedene Suchmaschinen steuern wollt.
Was Ihr beachten müsst, wenn Ihr das Crawlen und Indexieren Eurer Seite durch verschiedene Suchmaschinen steuern wollt.
Das Festlegen der Seiten, die von den Suchmaschinen gecrawlt und indexiert werden dürfen, ist nicht ganz einfach, vor allem dann, wenn mehrere Suchmaschinen berücksichtigt werden müssen. Dabei hilft es, die Arbeitsweise der Suchmaschinen zu kennen, um die richtigen Direktiven in robots.txt und Meta-Robots-Tags setzen zu können.
Crawlen und Indexieren sind zweierlei: Damit eine Seite indexiert werden kann, muss sie zunächst einmal gecrawlt, also zum Beispiel vom Googlebot abgerufen und analysiert werden. Das Crawlen einer Webseite wird über die robots.txt-Datei gesteuert: Dort wird angegeben, welche Seiten, Ressourcen und Pfade von den Suchmaschinen abgerufen werden dürfen. Dabei hat man die Möglichkeit, verschiedene Direktiven für verschiedene Suchmaschinen anzugeben.
Das Indexieren kann dagegen auf verschiedene Weisen gesteuert werden. Meist geschieht das mit Hilfe der Meta-Robots-Tags im HTML-Code oder auch über X-Robots-Tags im HTTP-Header. Dort gibt man an, ob eine Seite indeixert werden darf oder nicht ("noindex") und ob den Links auf der Seite gefolgt werden darf oder nicht ("nofollow").
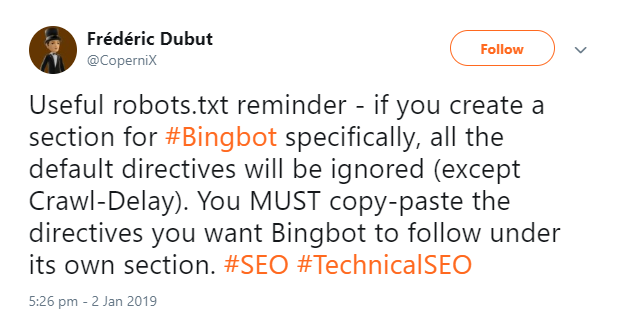
Wie genau gehen Google und Bing mit robots.txt und Meta-Robots-Tags um? Dazu gab es in dieser Woche einen Tweet eines Bing-Mitarbeiters. Darin wurde mitgeteilt, Bing ignoriere die Standard-Direktiven in der robots.txt, wenn es einen speziellen Abschnitt für den Bing-Bot gebe. Daher müsse man alle Direktiven, die für den Bingbot gelten sollen, in den speziellen Bereich kopieren.
Um die Arbeitsweise der Suchmaschinen in Bezug auf Crawling- und Indexierungs-Direktiven zu verstehen, werden diese im Folgenden nacheinander beschrieben.
Im oben gezeigten Tweet hatte Bing mitgeteilt, der Crawler ignoriere Direktiven im allgemeinen Teil der robots.txt, wenn es einen speziell für Bing definierten Bereich gebe. Das ist im Grunde nicht neu und gilt nicht nur für Bing, sondern auch für andere Suchmaschinen. Eine Eigenschaft von robots.txt-Dateien ist es, dass für unterschiedliche Suchmaschinen jeweils separat definiert werden kann, was sie dürfen und was nicht.
In einem konkreten Beispiel würde das bedeuten, dass Seiten, die im allgemeinen Teil der robots.txt gesperrt sind, im Bereich für Bing aber explizit freigegeben sind, vom Bingbot gecrawlt werden. Das gilt ebenso für den Googlebot.
Daher Vorsicht: Wer nicht möchte, dass eine Suchmaschine bestimmte Seiten crawlt, sollte überprüfen, dass diese nicht nur im allgemeinen Teil der robots.tx gesperrt sind, sondern auch im für die jeweiligen Suchmaschinen ausgewiesenen Bereich.
Im folgenden Beispiel gibt es drei Bereiche: einen, der für alle User-Agents gilt, sowie jeweils einen für den Googlebot und den Bingbot.

Obwohl im allgemeinen Bereich definiert ist, dass die Seiten /seite1.html und /seite2.html nicht gecrawlt werden dürfen, ist /seite1.html für den Googlebot freigegeben, nicht jedoch /seite2.html. Für den Bingbot gilt: Er darf /seite2.html crawlen, nicht jedoch /seite1.html.
Vom Crawlen zu trennen ist das Indexieren einer Seite: Per Meta-Robots-Tag lässt sich dieser Vorgang steuern. Dabei wird festgelegt, ob eine Seite indexiert werden darf oder nicht und ob den Links auf der Seite gefolgt werden darf oder nicht. Hierzu hatte Google kürzlich mitgeteilt, dass jeweils die strengste gefundene Direktive zählt. Wenn also auf einer Seite zugleich ein "index" und ein "noindex" enthalten sind, so zählt das "noindex" und die Seite wird nicht indexiert.
Das ist insbesondere dann von Bedeutung, wenn Meta-Robots-Tags nachträglich hinzugefügt werden, zum Beispiel per JavaScript. Wird per JavaScript ein "noindex" hinzugefügt, berücksichtigt Google dieses. Gibt es im statischen HTML ein "nofollow", das per JavaScript entfernt wird, wertet Google das "nofollow" dennoch.
Von Bing gibt es dazu keine entsprechende Aussage. Um sicher zu gehen, sollte man daher überprüfen, ob die gewünschte Direktive im statischen HTML vorhanden ist und ob es zu nachträglichen Änderungen per JavaScript kommt.
Zur Verwirrung hatte eine irrtümliche Verbindung des oben genannten Bing-Tweets mit Googles Aussage zum Umgang mit Meta-Robots-Direktiven geführt. Beides hat jedoch nichts miteinander zu tun. Darauf wurde auch in einem Tweet von Screaming Frog hingewiesen:
Neben den Meta-Robots-Tags lässt sich die Indxierung auch per X-Robots-Tag im HTTP-Header steuern. Der große Vorteil hier ist, dass im Gegensatz zu den Meta-Robots-Tags eine individuelle Behandlung verschiedener Suchmaschinen möglich ist. Man kann also zum Beispiel die Indexierung durch Google erlauben, sie aber für Bing ausschließen. Zudem kann per X-Robots-Tag auch die Indexierung von Ressourcen wie Bilddateien gesteuert werden.
Man sieht: Um zu entscheiden, welche Seiten gecrawlt und indexiert werden dürfen und welche nicht, sollte man wissen, wie die einzelnen Suchmaschinen mit den Direktiven umgehen. Wer Google und Bing unterschiedlich behandeln möchte, kann dies für das Crawlen in der robots.txt vornehmen und für das Indexieren per X-Robots-Tag. Meta-Robots-Tags erlauben dagegen nur das Festlegen der Indexierung für alle Suchmaschinen gemeinsam.
Neben Google und Bing gibt es natürlich noch weitere Suchmaschinen, die relevant sein könnten, wie zum Beispiel Yandex und Baidu. Wie diese Suchmaschinen mit den Direktiven zum Crawlen und Indexieren umgehen, solltet Ihr Euch am besten in deren Dokumentationen ansehen. Es ist aber davon auszugehen, dass sich auch diese Suchmaschinen an den Standards für robots.txt und Meta-Robots-Tags orientieren.
Titelbild: Paul Pirosca - Fotolia.com


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
