

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.

Google hat die Dokumentation zum Crawl-Statusreport aktualisiert. Demnach stellt Google bei nicht verfügbarer robots.txt nach 30 Tagen das Crawlen ein, wenn die Homepage einer Website nicht erreichbar ist.


In Googles Dokumentation zum Crawl-Statusreport der Search Console gibt es eine Reihe interessanter Änderungen. Es ist jetzt noch besser ersichtlich, wie Google im Falle einer nicht erreichbaren robots.txt reagiert und welche Konsequenzen sich für das Crawlen ergeben. Außerdem gibt es einige wichtige Änderungen, was die Reaktion des Googlebots betrifft. Entdeckt und auf Twitter geteilt hat sie SEO Brodie Clark:
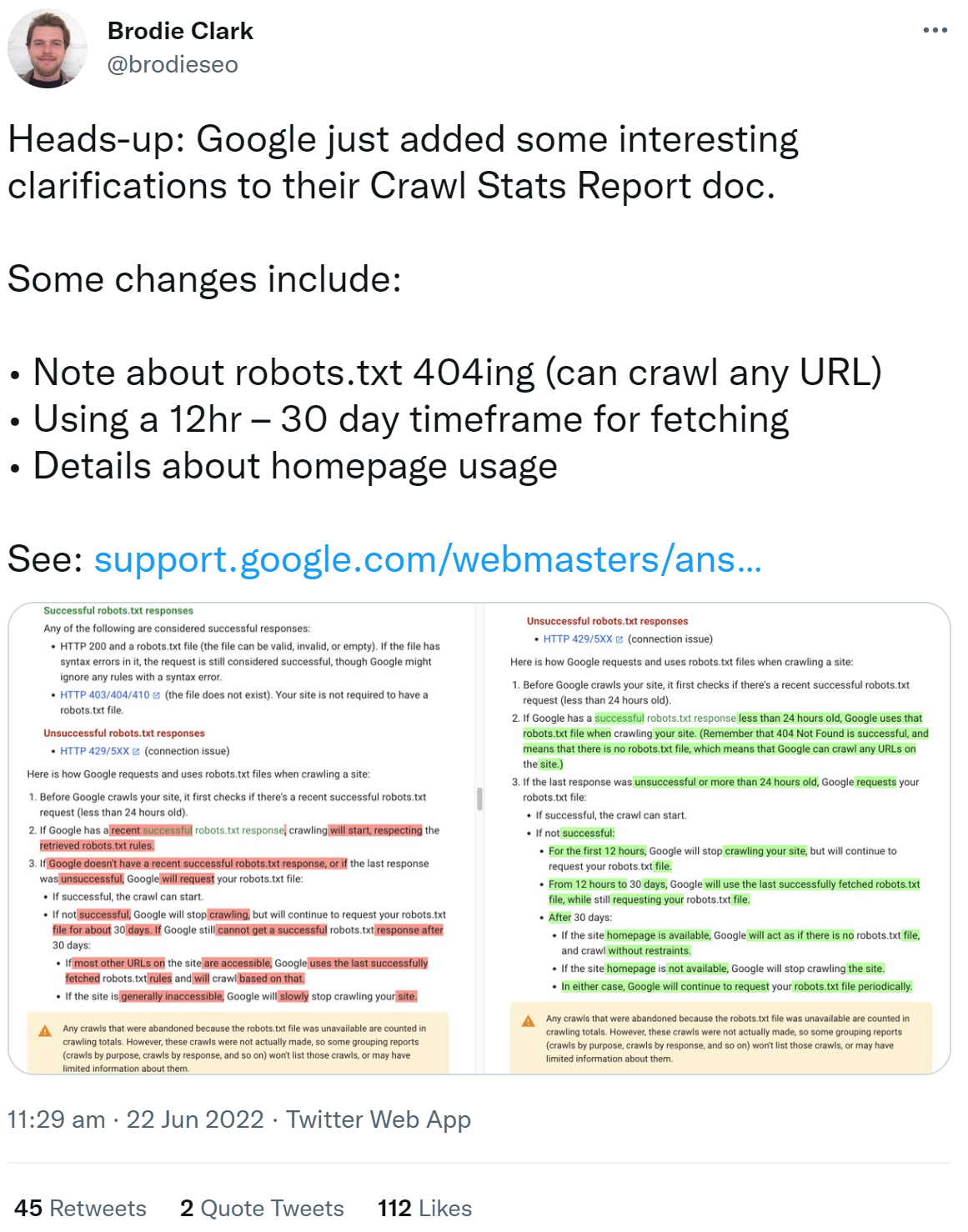
Nachfolgend sind die wichtigsten Änderungen in der Dokumentation zusammengefasst:
Wenn Google eine erfolgreiche Antwort auf den Abruf der robots.txt erhalten hat, die aktueller als 24 Stunden ist, dann verwendet Google diese robots.txt zum Crawlen (ergänzt wurde der Zeitraum von 24 Stunden). Ergänzt wurde außerdem der Hinweis, dass ein 404 beim Abruf der robots.txt als erfolgreicher Abruf gilt. Dies wird so behandelt, als gebe es keine robots.txt. Google kann damit jede URL der Website crawlen.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Neu sind auch die folgenden Zeiträume: Bei nicht erfolgreichem Abruf der robots.txt wird Google für 12 Stunden das Crawlen der Website unterbrechen. Nach 12 Stunden und bis zu 30 Tagen wird Google die zuletzt erfolgreich abgerufene robots.txt zum Crawlen verwenden. Nach 30 Tagen wird Google die komplette Website crawlen, sofern die Homepage verfügbar ist und so handeln, als gebe es keine robots.txt. Sollte die Homepage der Website nicht verfügbar sein, wird Google das Crawlen der Website abbrechen. Allerdings wird Google weiterhin regelmäßig versuchen, die robots.txt abzurufen.
Zuvor hatte es geheißen, Google crawle eine Website bei nicht verfügbarer robots.txt nach 30 Tagen, wenn die meisten URLs der Website verfügar seien. Dabei würde die letzte erfolgreich abgerufene robots.txt verwendet.
Im Gegensatz zu einem 404 gilt übrigens ein 403 nicht als erfolgreicher Abruf einer robots.txt. Das gilt auch und insbesondere für 500er-Fehler.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
