Eine aktuelle Studie zeigt, dass die Empfehlungen von Marken und Produkten durch KI-Tools kaum reproduzierbar sind. Wenn man ein KI-Tool 100 Mal bittet, Empfehlungen zu geben, liegt die Wahrscheinlichkeit, zweimal die gleiche Liste zu bekommen, unter eins zu hundert.
Eine neue Untersuchung von Rand Fishkin (SparkToro) und Gumshoe.ai liefert datengestützte Antworten zur Reproduzierbarkeit von KI-Empfehlungen bei Tools wie ChatGPT, Claude und Google AI. Die Ergebnisse zeigen klar die Grenzen der Möglichkeiten auf, die Sichtbarkeit von Marken und Produkten in KI-Tools zu tracken.
Die Illusion der Reproduzierbarkeit
Das vielleicht schockierendste Ergebnis der Studie ist die extreme Inkonsistenz von KI-Modellen. KIs fungieren nicht als Datenbanken, die Fakten abrufen, sondern als “Probability Engines”, also als von der Wahrscheinlichkeit getriebene Tools. Das zeigen einige Erkenntnisse der Studie:
- Zufällige Listen: Wenn man ein KI-Tool 100 Mal bittet, Marken oder Produkte zu empfehlen, ist die Wahrscheinlichkeit, zweimal dieselbe Liste zu erhalten, geringer als 1 zu 100.
- Zufällige Reihenfolge: Die Wahrscheinlichkeit, dieselbe Liste in der gleichen Reihenfolge zu erhalten, liegt sogar bei unter 1 zu 1.000.
- Variable Anzahl: Selbst die Anzahl der empfohlenen Elemente variiert stark; manchmal werden nur 2-3 Optionen genannt, in anderen Durchläufen 10 oder mehr.
So muss man zum Beispiel Claude 1.429mal fragen, bis man zweimal eine Antwort mit denselben Marken in der gleichen Reihenfolge erhält:
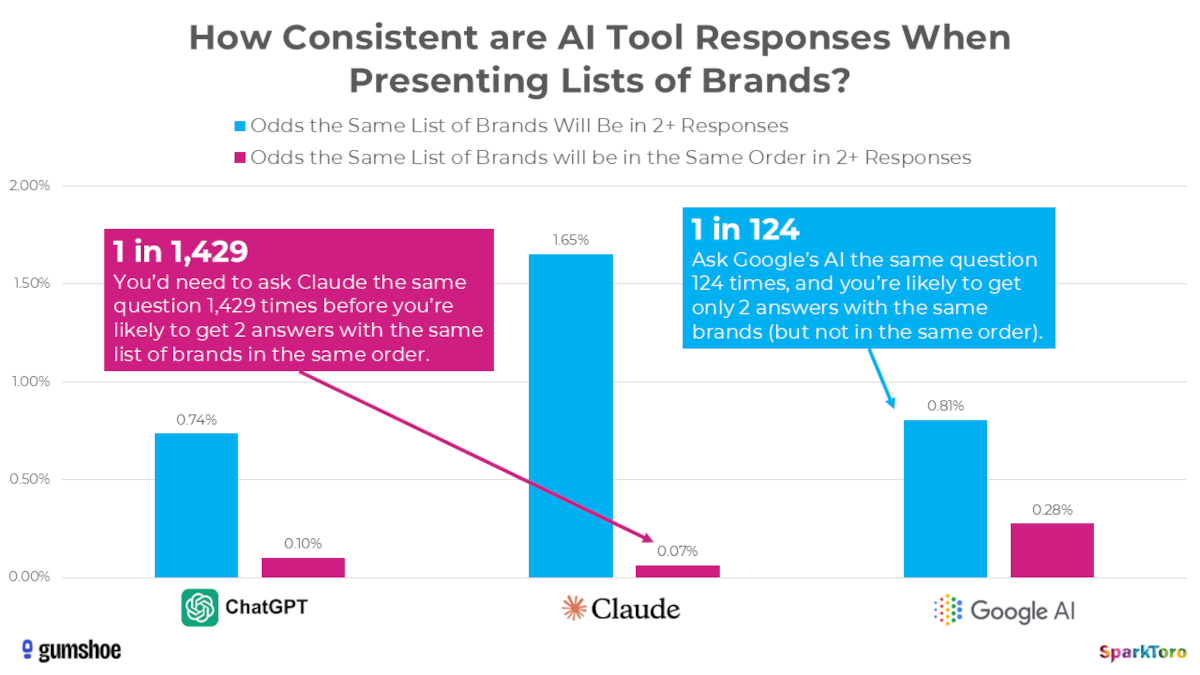
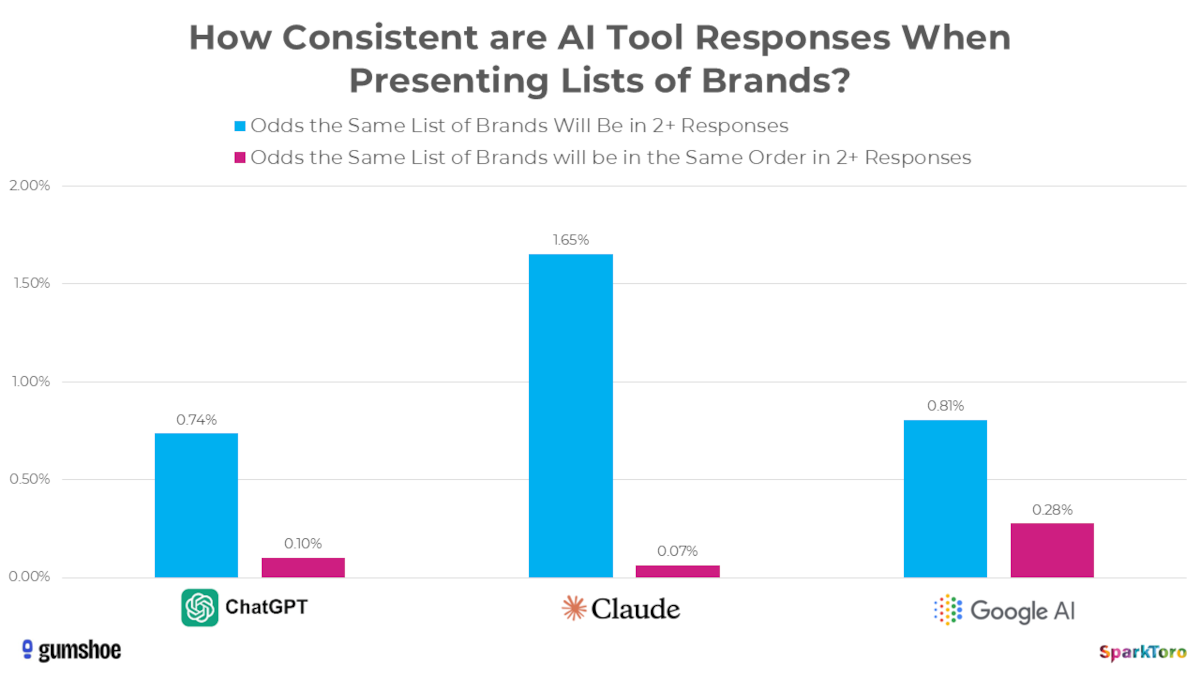
Dabei zeigen die KI-Tools eine unterschiedlich ausgeprägte Konsistenz bei der Zusammensetzung von Markennennungen. Die Wahrscheinlichkeit, dass dieselben Marken in mindestens zwei Antworten erwähnt werden, war bei Claude mit 1,65 Prozent am höchsten, bei ChatGPT mit 0,74 Prozent am geringsten. Die Wahrscheinlichkeit, dass dieselben Marken in der gleichen Reihenfolge in mindestens zwei Antworten erscheinen, war bei Google mit 0,28 Prozent am höchsten und bei ChatGPT mit 0,1 Prozent am geringsten.
Die Zahl der von den KI-Tools in ihren Antworten genannten Marken schwankt sehr stark und hängt davon ab, wie viele Marken in den Trainingsdaten vorkommen. Die folgende Grafik zeigt die Zahl der Unique Brands nach KI-Tool und Thema, basierend auf 12 verschiedenen Prompts, von denen jeder 60 bis 100mal durchgeführt wurde:
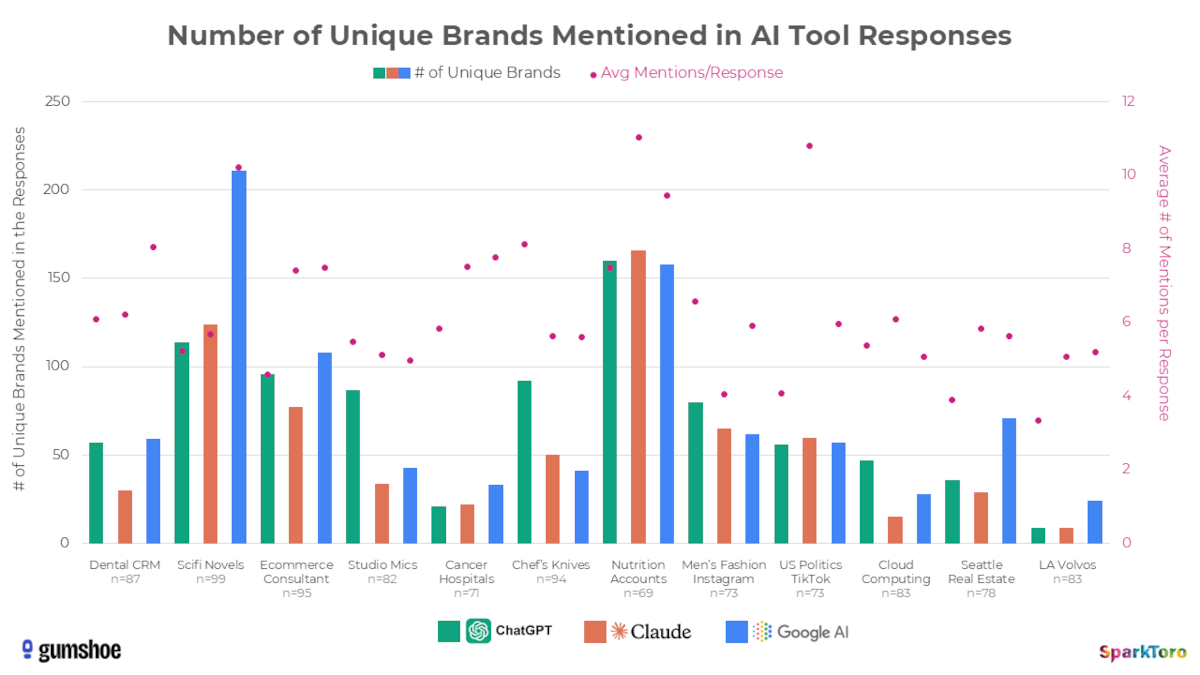
Diese Ergebnisse zeigen deutlich: KI-Tools liefern keine konsistenten Listen von Marken- oder Produktempfehlungen. Wer eine Antwort nicht mag oder seine Marke vermisst, müsste die KI theoretisch nur ein paar Mal öfter fragen, um ein anderes Ergebnis zu erhalten.
Das passt zur allgemein bekannten Eigenschaft von LLMs, dass deren Ergebnisse nicht vorhersagbar, also nicht deterministisch sind.
Probleme beim Tracking von KI-Sichtbarkeit
Aufgrund der oben genannten Zufälligkeit ist das klassische Tracking von Ranking-Positionen (z. B. „Wir sind auf Platz 1 bei ChatGPT“) sinnlos. Bei LLMs handelt es sich nicht um Suchmaschinen. Deshalb gibt es dort auch keine klassischen Rankings. Ein Tracking von “Rankings” in KI-Ergebnissen wäre ohnehin sinnlos.
SEO-Beratung: Wir sind Ihre Experten
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.

Christian Kunz
SEO Experte

David Wulf
SEO Experte

Sven Häwel
Offpage-Experte
Ein Beispiel aus der Studie verdeutlicht das: Das „City of Hope“-Krankenhaus erschien in 69 von 71 Antworten von ChatGPT auf eine bestimmte Anfrage. In den spezifischen „Rankings“ dieser Listen war es jedoch nur in 25 Fällen an erster Stelle. Die Positionierung innerhalb der Liste ist also purer Zufall und lässt keine Rückschlüsse auf die tatsächliche Relevanz zu. Jedes Tool, das eine feste „Ranking-Position“ in KI-Antworten ausgibt, liefert laut der Studie irreführende Daten.
Das gilt übrigens auch für Antworten der Google AI Overviews und des Google AI Modes. Die Wahrscheinlichkeit, dass dieselben Marken in der gleichen Reihenfolge in zwei aufeinanderfolgenden Suchanfragen genannt werden, liegt nahezu bei null. Und die Wahrscheinlichkeit, dass wenigstens dieselben Marken genannt werden - unabhängig von der Reihenfolge - lag bestenfalls bei knapp sieben Prozent. Und das auch nur, weil es bei den betreffenden Suchanfragen nur wenige Anbieter gab, die in Frage kamen. Bei anderen Suchanfragen mit größerer Auswahl tendierte die Wahrscheinlichkeit auch hier gegen null.

Die Lösung: Sichtbarkeitsrate
Obwohl die Listen zufällig sind, gibt es Hoffnung. Die Untersuchung zeigt, dass bestimmte Marken über hunderte von Durchläufen hinweg konsistent auftauchen, wenn sie vom KI-Modell stark mit dem Thema assoziiert werden.
Auch wenn die Reihenfolge variiert, ist die prozentuale Häufigkeit, mit der eine Marke in den Antwortsets erscheint, statistisch valide. Das gilt sowohl für synthetische Prompts als auch für sehr diverse, von Menschen geschriebene Prompts.
Prompts: die menschliche Variable
Ein weiteres Problem beim Tracking ist die enorme Vielfalt menschlicher Eingaben. In der Studie mit 142 Teilnehmern gab es kaum zwei Prompts, die sich ähnelten; die semantische Ähnlichkeit war extrem gering. Nutzer suchen nicht mit logischen Keywords, sondern mit kreativen, spezifischen Beschreibungen.
Dennoch gibt es eine gute Nachricht für Websitebetreiber: Trotz der extrem unterschiedlichen Formulierungen der Nutzer erkannten die KI-Tools oft die zugrundeliegende Absicht (Intent) und lieferten relativ konsistente Sets an Markenempfehlungen. Beispielsweise tauchten Kopfhörer-Marken wie Bose oder Sony in 55–77 % der Antworten auf, egal wie "seltsam" oder spezifisch der Prompt formuliert war.
Maßnahmen für SEOs und Websitebetreiber
Basierend auf diesen Erkenntnissen lassen sich konkrete Handlungsanweisungen für SEOs ableiten:
- Tracken von Rankings ist sinnlos: Das Ziel, auf „Platz 1“ in einer KI-Antwort zu stehen, ist falsch gesetzt. Weil die Reihenfolge ein statistisches Lotteriespiel ist, ist diese Metrik wertlos.
- Fokus auf die Sichtbarkeitsrate: Die einzige verlässliche Kennzahl ist, wie oft eine Marke in einem Set von Antworten auftaucht. Um das zu messen, müssen Prompts dutzende bis hunderte Male ausgeführt werden.
- Transparenz von Tool-Anbietern: Tools, die keine statistisch fundierten, öffentlich überprüfbaren Daten liefern, bringen wenig. Anbieter müssen offenlegen, wie sie mit der Varianz der KI-Antworten umgehen.
- Funktionsweise verstehen: KIs sind keine “Wahrheitsquellen”, sondern basieren auf Wahrscheinlichkeiten. Eine hohe Sichtbarkeit bedeutet lediglich, dass das Modell eine Marke stark mit dem Themengebiet assoziiert.
- Aggregierte Daten nutzen: Um verlässliche Daten zu erhalten, müssen Anfragen 60 bis 100 Mal wiederholt werden, die Ergebnisse gemittelt und die prozentuale Sichtbarkeit berechnet werden. Einzelne Stichproben sind bedeutungslos.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















