

Google: Neue Hilfeseite gibt Tipps zur Auswahl von SEO- und GEO-Anbietern und -Tools
Google gibt auf einer neuen Hilfeseite Tipps dazu, was man bei der Wahl eines SEO- oder GEO-Dienstleisters beachten sollte.
 Das SEO-Tool Screaming Frog wurde in der Version 7 veröffentlicht. Zu den neuen Funktionen zählt zum Beispiel die Möglichkeit, gecrawlte Seiten rendern zu lassen.
Das SEO-Tool Screaming Frog wurde in der Version 7 veröffentlicht. Zu den neuen Funktionen zählt zum Beispiel die Möglichkeit, gecrawlte Seiten rendern zu lassen.
Screaming Frog 7 ist wieder ein großer Wurf geworden. Mit den neuen Funktionen dieser Version lassen sich Analysen durchführen, die noch näher am Crawler von Google liegen. Interessant ist vor allem die Möglichkeit zum Rendern gecrawlter Seiten.
Das alles ist neu bei Screaming Frog 7:
In einem neuen Tab kann man jetzt eine gerenderte Ansicht gecrawlter Seiten sehen. Die Ansicht erscheint im unteren Bereich der Benutzeroberfläche von Screaming Frog, wenn im JavaScript-Rendering-Modus gecrawlt wird. Das ist vor allem für dynamisch erzeugte Webseiten interessant, denn damit lässt sich prüfen, ob sich die Seite auch für den Googlebot richtig darstellt.
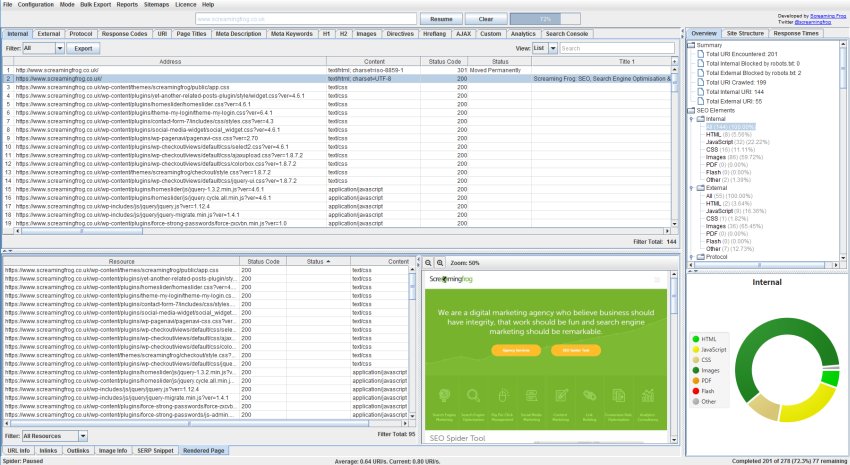
Zusätzlich lassen sich verschiedene Szenarios testen, indem man beispielsweise den AJAX-Timeout oder die Größe des Viewports definiert.
Screaming Frog 7 liefert jetzt einen Überblick über blockierte Ressourcen, die einzeln für jede gerenderte Seite angezeigt werden:
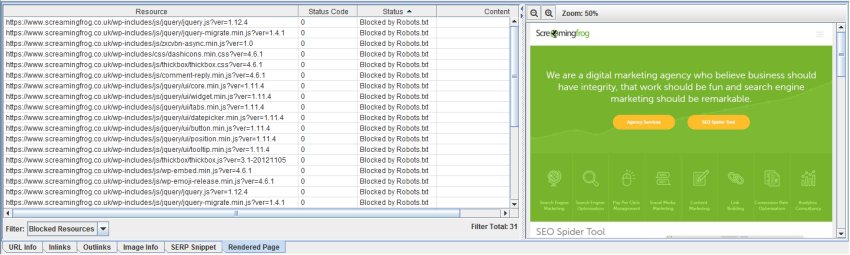
Möglich ist jetzt auch das Herunterladen, Editieren und Testen der robots.txt einer Seite. Die zugehörige Funktion nennt sich "Custom robots.txt". Damit lassen sich auch verschiedene robots.txt-Dateien auf Subdomain-Ebene hinzufügen, Direktiven testen und URLs ansehen, die davon betroffen wären. Die Funktion nutzt den User-Agent, der in der Konfiguration festgelegt wurde. In Kombination mit der neuen Funktion "Fetch & Render" lässt sich schnell erkennen, ob es zu Problemen mit durch die robots.txt blockierten Daten kommt.
Endlich beherrscht Screaming Frog auch den Umgang mit hreflang-Attributen. Dabei werden sowohl die im HTML-Quellcode als auch die per HTTP-Header gesetzten hreflangs berücksichtigt. Auch die Extraktion aus Sitemaps ist möglich. Zusätzlich lassen sich verbreitete Fehler leichter aufdecken, die im Zusammenhang mit der Verwendung von hreflang gemacht werden. Dazu gehören zum Beispiel Statuscodes jenseits der 200, fehlende oder inkonsistente Sprachlinks etc.
Eine ebenfalls schon länger vermisste und erwünschte Funktion von Screaming Frog bezieht sich auf die Prüfung der Paginierung von Artikeln, die sich über mehrere Seiten erstrecken. Screaming Frog zeigt jetzt Fehler an, die in Verbindung mit den Paginierungslinks stehen. Auch kann man jetzt auf einen Blick erkennen, wenn das Gegenstück eines rel="next"- oder eines rel="prev"-Links fehlt.
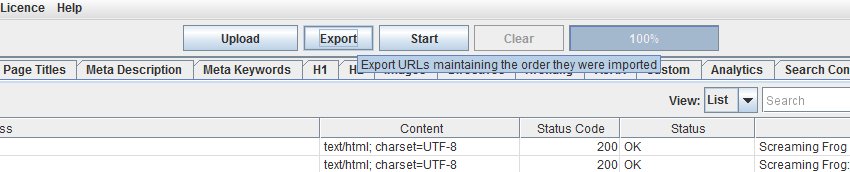
Bisher konnte es bei Screaming Frog zu einer Umstellung der Reihenfolge der URLs kommen, nachdem diese hochgeladen und gecrawlt wurden. Das lag an verschiedenen Umformatierungen und Normalisierungen, die im Hintergrund geschehen sind. Jetzt bietet Screaming Frog die Möglichkeit, die Reihenfolge beizubehalten. Um die entsprechende Liste zu exportieren, wurde ein neuer Button hinzugefügt.
Neu ist auch, dass man mit Screaming Frog jetzt auch Seiten testen kann, die mit einem über die Standard-Authentifizierung hinausgehenden Login geschützt sind. Mit Hilfe der neuen Konfiguration kann man die Login-Daten für jedes beliebige Webformular definieren.




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
