

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 Das Verwenden von 'noindex' in der robots.txt kann unter Umständen wie ein 'disallow' wirken, entspricht aber nicht dem Zweck der Datei. Daher sollte man sich nicht darauf verlassen, dass eine solche Lösung zuverlässig funktioniert.
Das Verwenden von 'noindex' in der robots.txt kann unter Umständen wie ein 'disallow' wirken, entspricht aber nicht dem Zweck der Datei. Daher sollte man sich nicht darauf verlassen, dass eine solche Lösung zuverlässig funktioniert.
Die robots.txt dient dazu, bestimmte Seiten und Verzeichnisse für die Bots der Suchmaschinen zu sperren oder diese explizit freizugeben. Dabei geht es ausdrücklich um das Crawlen, nicht aber um das Indexieren.
Manchmal ist aber zu beobachten, dass bestimmte robots.txt-Dateien auch Anweisungen enthalten, die sich auf das Indexieren beziehen, wie zum Beispiel "noindex"-Direktiven. So etwas kann sich wie ein "disallow" auswirken, entspricht aber nicht den offiziellen Standards für die Verwendung der robots.txt.
Wenn man auf eine solche Lösung setzt und Seiten per robots.txt und "noindex" sperren möchte, sollte man immer eine zusätzliche Absicherung verwenden. Darauf hat Johannes Müller per Twitter hingewiesen:
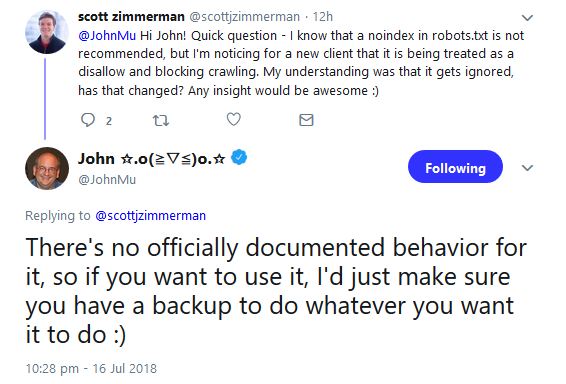
Es gilt also folgende Regel: Das Ausschließen von Seiten und Verzeichnissen für das Crawlen geschieht in der robots.txt per "disallow", das Sperren gegen Indexierung geschieht per Robots-Meta-Tag "noindex" odet durch ein entsprechendes X-Robots-Tag im HTTP-Header.
Titelbild: Copyright AKS - Fotolia.com

{loadpositoin newsletter}


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
