
Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
 Das Crawlen einer Seite ist nicht unbedingt nötig, damit Google sie indexiert. Allerdings werden dabei die Inhalte der Seite nicht übernommen.
Das Crawlen einer Seite ist nicht unbedingt nötig, damit Google sie indexiert. Allerdings werden dabei die Inhalte der Seite nicht übernommen.
Normalerweise umfasst der Prozess für die Aufnahme neuer Webseiten in den Google-Index die folgenden Schritte:
Google kann aber auch Seiten indexieren, ohne sie zuvor gecrawlt zu haben. Das passiert, wenn eine Seite per robots.txt gesperrt ist. In diesem Fall werden die Inhalte der Seite nicht erfasst - dennoch kann sie in der Google-Suche gefunden werden.
Auf diesen Sonderfall wies Johannes Müller auf Twitter hin:
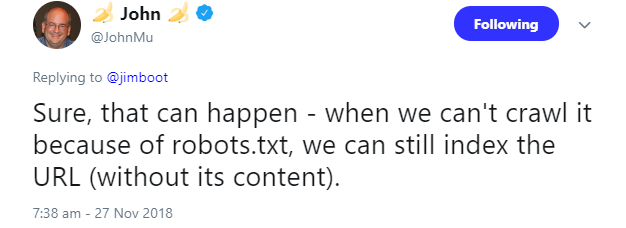
Auch in der Google-Hilfe ist dies dokumentiert. Dort wird beschrieben, dass Google auch Seiten ohne Zugriff auf deren Inhalte indexieren könne.
Ein Grund, der dazu führen kann, ist, dass eine Seite, die per robots.txt gesperrt ist, von anderen Seiten verlinkt ist. In diesem Fall findet der Googlebot die Seite und übernimmt sie in den Index.
In den Suchergebnissen erscheinen Seiten, die auf diese Weise indexiert wurden, ohne Description, weil diese vom Crawler nicht erfasst wurde:
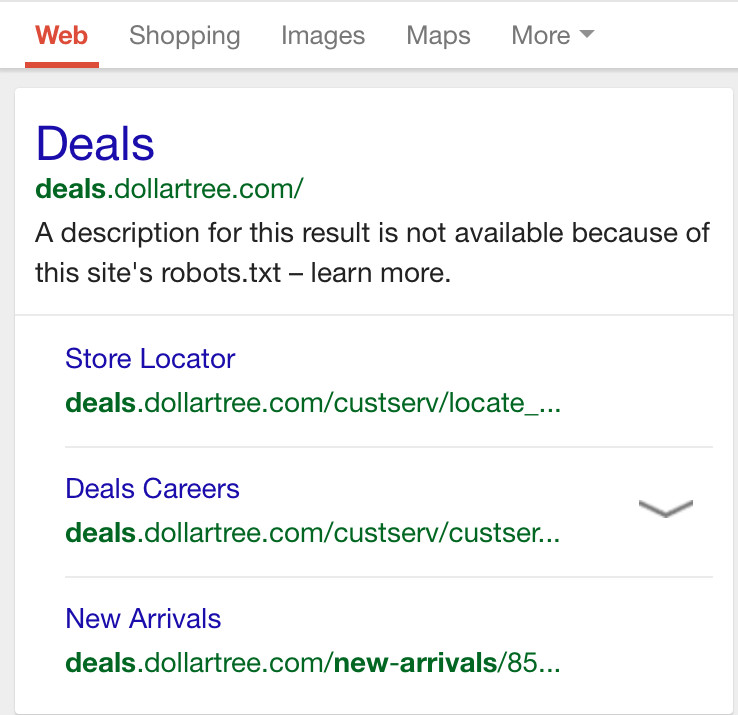
Wenn eine Seite nicht indexiert werden soll, muss dies per Meta Robots-Attribut erfolgen, das auf "noindex" gesetzt werden muss.
Die wichtigsten Informationen zum Vorgehen beim Sperren von Seiten per robots.txt und "noindex" sind hier zu finden.


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
