
Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 Um zu steuern, welche Seiten von Google und anderen Suchmaschinen gecrawlt und indexiert werden sollen, kann man die robots.txt-Datei und das Meta Robots-Attribut verwenden. Vielen Webmastern ist aber unklar, wann sie welches Instrument einsetzen sollten. Um das zu verstehen, muss vor allem die Funktionsweise der Suchmaschinen bekannt sein.
Um zu steuern, welche Seiten von Google und anderen Suchmaschinen gecrawlt und indexiert werden sollen, kann man die robots.txt-Datei und das Meta Robots-Attribut verwenden. Vielen Webmastern ist aber unklar, wann sie welches Instrument einsetzen sollten. Um das zu verstehen, muss vor allem die Funktionsweise der Suchmaschinen bekannt sein.
Es ist eine der ewigen Fragen in der SEO: Sollte man Seiten per robots.txt oder per 'noindex'-Attribut sperren? Dabei wird oft vergessen, dass diese beiden Methoden nichts miteinander zu tun haben, denn die robots.txt bezieht sich auf das Crawlen der Seiten, während das 'noindex'-Attribut aussagt, dass die betreffende Seite nicht indexiert werden soll. Um dies ein wenig zu verdeutlichen, folgt zunächst eine Beschreibung der grundsätzlichen Funktionsweise von Suchmaschinen.
Im Grunde ist das Prinzip, nach denen Suchmaschinen arbeiten, recht simpel: Aus der großen Menge von Webseiten werden einige Seiten als Startpunkt ausgewählt. Ausgehend von diesen Seiten werden über die dort vorhandenen Links weitere Seiten aufgerufen. Die dort vorgefundenen Inhalte wie Texte und Metadaten werden ausgelesen und bereinigt. Das alles übernimmt ein Crawler wie beispielsweise der Googlebot.
Die vorgefundenen Daten werden in einer Datenbank gespeichert. Erfasste URLs werden in eine Warteliste eingetragen, und die betreffenden Seiten werden zu einem späteren Zeitpunkt aufgerufen.
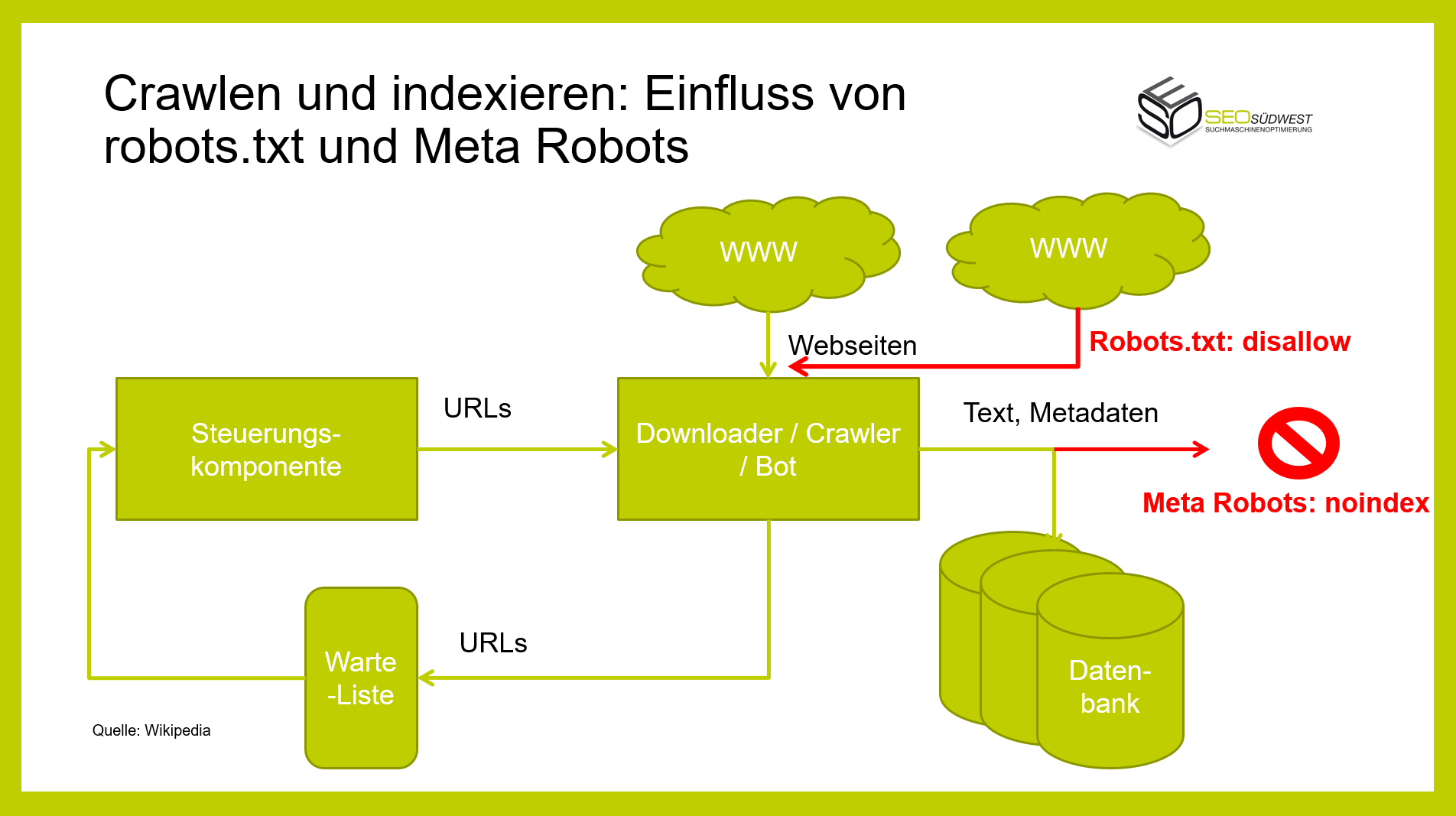
Anhand dieses Prozesses kann verdeutlicht werden, wo robots.txt und "noindex" ansetzen: Seiten, die in einer robots.txt-Datei gesperrt sind, werden vom Crawler gar nicht erst aufgerufen. Die dort vorhandenen Inhalte inklusive der dort vorhandenen Links bleiben der Suchmaschine also verborgen.
Falls das Meta Robots-Attribut "noindex" gesetzt ist, werden die auf einer Seite gefundenen Inhalte zwar gecrawlt, aber nicht indexiert. Zudem werden die dort gefundenen Links über kurz oder lang nicht mehr gewertet.
Die Darstellung zeigt, dass das Sperren per robots.txt und "noindex" völlig unterschiedliche Effekte hat. Je nach gewünschtem Verhalten der Suchmaschine muss das eine oder das andere Instrument gewählt werden. Man sollte sich dazu folgende Fragen stellen:
Ein besonders häufiger Fehler, der im Zusammenspiel mit der robots.txt-Datei begangen wird, ist der folgende: Eine Seite ist bereits bei Google indexiert, soll aber aus dem Index entfernt werden. Anstatt nun die Seite per "noindex" zu kennzeichnen, wird sie in der robots.txt per "disallow" gesperrt. Das hat aber zur Folge, dass die Seite weiterhin im Index verbleibt, Google aber keine Description mehr im Snippet anzeigt, sondern lediglich einen Hinweis, dass die Seite per robots.txt gesperrt ist:
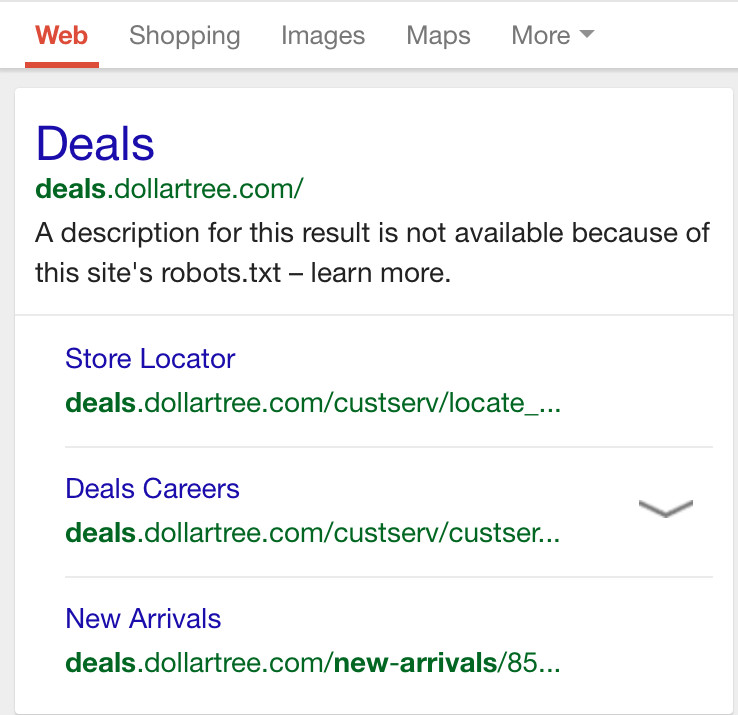
Das richtige Vorgehen in diesem Fall wäre also, die Seite zunächst per Meta Robots auf "noindex" zu setzen. Wenn die Seite aus dem Index entfernt wurde, kann sie anschließend per "disallow" in der robots.txt für die Crawler gesperrt werden.
Das Crawlen einzelner Seiten durch die Suchmaschinen wird per robots.txt-Datei gesteuert, das Indexieren per Meta Robots-Attribut. Vorsicht ist geboten, wenn bereits indexierte Seiten per robots.txt-Datei gesperrt werden - in diesem Fall kann es zu unerwünschten Effekten auf den Suchergebnisseiten kommen.
Titelbild: Google


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
