

Google: 404-Fehler sind ok, Links auf 404-Seiten sollten aber behoben werden
404-Fehler auf Websites sind laut John Müller von Google ok. Links, die zu einem 404-Fehler führen, sollten aber angepasst werden.
 Google hört nicht mit dem Crawlen von 404-Seiten auf, solange es Signale wie zum Beispiel Links gibt, die auf diese Seiten verweisen.
Google hört nicht mit dem Crawlen von 404-Seiten auf, solange es Signale wie zum Beispiel Links gibt, die auf diese Seiten verweisen.
Auch nach längerer Zeit versucht Google immer wieder, Seiten zu crawlen, die den Status 404 zurückgeben. Das passiert zumindest so lange, wie es Signale gibt, welche auf die betreffenden URLs verweisen. Selbst zufällige Links genügen, damit es der Googlebot immer wieder einmal mit dem Crawlen probiert. Das bestätigte Johannes Müller jetzt per Twitter. Ein Nutzer wollte zuvor wissen, ob es eine bestimmte Zeitspanne gebe, nach welcher Google das Crawlen einer 404-Seite einstelle:
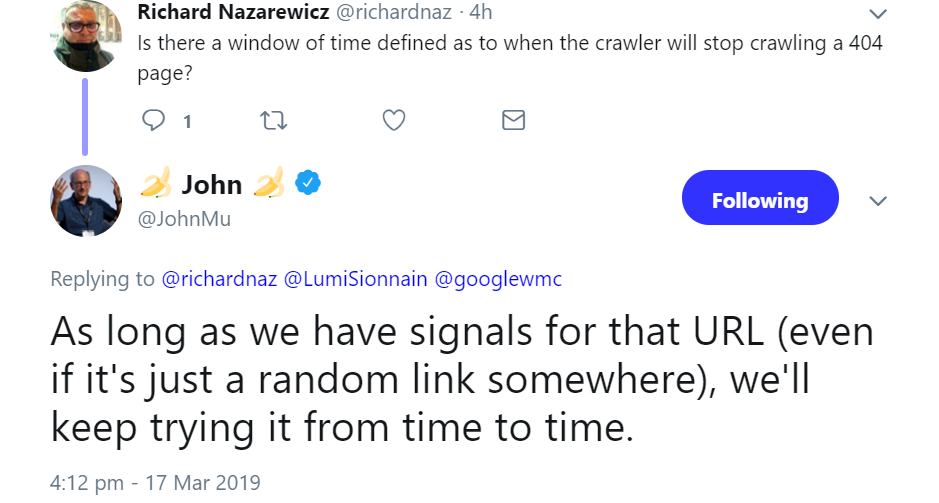
Das bedeutet: Möchte man tatsächlich vermeiden, dass Google eine bestimmte URL aufruft, sollte man dafür sorgen, dass es keine verweisenden Links mehr gibt. Alternativ kann man auch in der robots.txt die betreffenden URLs für das Crawlen sperren.
Titelbild: Copyrigt Dirk Schumann - Fotolia.com













![]()

![]()
![]()
![]()
