

Google Search Console: keine Indexierungsdaten vor dem 15. Dezember
Im Indexierungsbericht der Google Search Console fehlen die Daten vor dem 15. Dezember 2025. Das sind Nachwirkungen eines älteren Problems.
 Obwohl Google immer die Unterstützung von Indexierungs-Direktiven wie 'noindex' in der robots.txt bestritten hat, scheint dies zumindest in manchen Fällen zu funktionieren. Doch damit wird wohl demnächst Schluss sein.
Obwohl Google immer die Unterstützung von Indexierungs-Direktiven wie 'noindex' in der robots.txt bestritten hat, scheint dies zumindest in manchen Fällen zu funktionieren. Doch damit wird wohl demnächst Schluss sein.
Noch einmal zur klaren Unterscheidung: Die robots.txt dient dazu, das Crawlen einer Website zu steuern. Damit wird also geregelt, welche Suchmaschinen-Bots welche Seiten und Verzeichnisse einer Website aufrufen dürfen und welche nicht.
Davon zu trennen ist die Steuerung der Indexierung, also die Kontrolle darüber, ob bestimmte Seiten in die Suchergebnisse aufgenommen werden sollen oder nicht. Das wird entweder per Meta-Robots-Tag oder per X-Robots-Tag im HTTP-Header gesteuert.
Manche Webmaster nutzen die robots.txt aber nicht nur zum Steuern des Crawlens, sondern auch für die Kontrolle darüber, welche Inhalte indexiert werden dürfen. Dazu schreiben sie in die robots.txt einfach Zeilen wie
Noindex: /seite-1/
Noindex: /seite-2/
Google hat stets bestritten, dies zu unterstützen. Dennoch scheint es zumindest in manchen Fällen zu funktionieren.
Damit könnte aber bald Schluss sein, denn Gary Illyes von Google kündigte an, die entsprechenden Codezeilen des Googlebots womöglich zu entfernen, weil die Vermischung von Crawlen und Indexieren an dieser Stelle einfach unpassend sei:
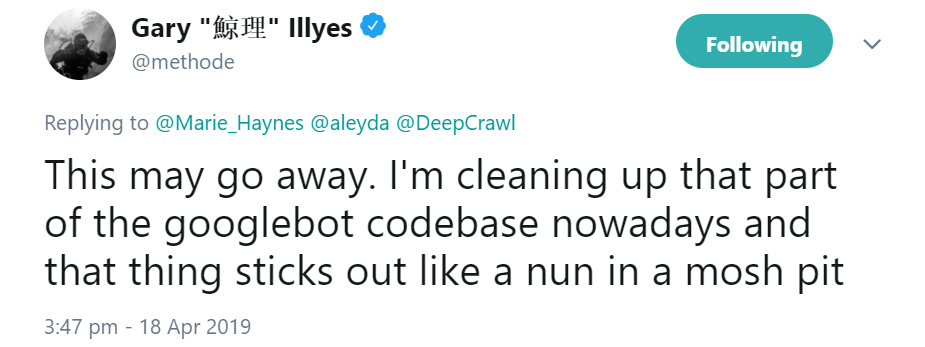
Auf den Einwand, die Steuerung der Indexierung per robots.txt sei einfacher zu handhaben, kündigte Illyes an, man wolle die Entwickler zur richtigen Verwendung erziehen:
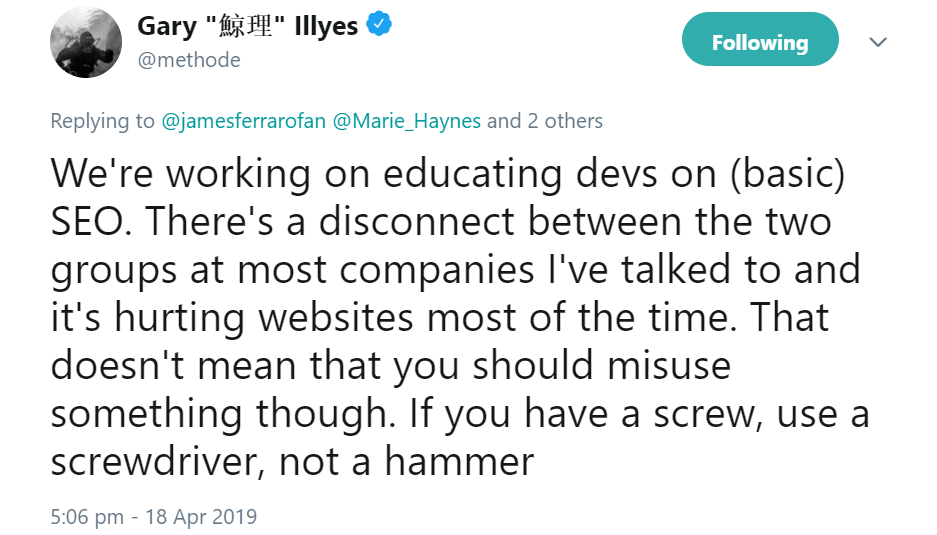
Um sicher zu gehen, sollte man also eine klare Trennung vornehmen: Das Steuern des Crawlens geschieht in der robots.txt, das Steuern der Indexierung erfolgt per Meta-Robots-Tags oder per X-Robots-Tags.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
