
KI-Bots: Google rät von zusätzlichen Content-Direktiven in robots.txt ab
John Müller von Google rät von zusätzlichen Content-Direktiven in der robots.txt ab, die zur Steuerung von KI-Bots verwendet werden sollen.
 Wer nach dem 1. September 'noindex'-Regeln in der robots.txt belässt, muss keinen Schaden für die Darstellung in den Google-Ergebnissen fürchten. Einen Nutzen bringt dies allerdings auch nicht.
Wer nach dem 1. September 'noindex'-Regeln in der robots.txt belässt, muss keinen Schaden für die Darstellung in den Google-Ergebnissen fürchten. Einen Nutzen bringt dies allerdings auch nicht.
Gestern hatte Google damit begonnen, Webmaster zu informieren, die "noindex"-Regeln in der robots.txt verwenden. Sie werden in der Nachricht aufgefordert, "noindex" aus der robots.txt zu entfernen. Google hatte zuvor angekündigt, ab dem 1. September den Support für "noindex" in der robots.txt einzustellen, obwohl Google diese Verwendungsart nie offiziell unterstützt hatte.
Wer über den 1. September hinaus "noindex" in der robots.txt belässt, muss aber keinen Schaden befürchten. Das erklärte Johannes Müller per Twitter. Die Regeln würden einfach keine Wirkung mehr zeigen, und es ergäbe sich dadurch ein höherer Wartungsaufwand:
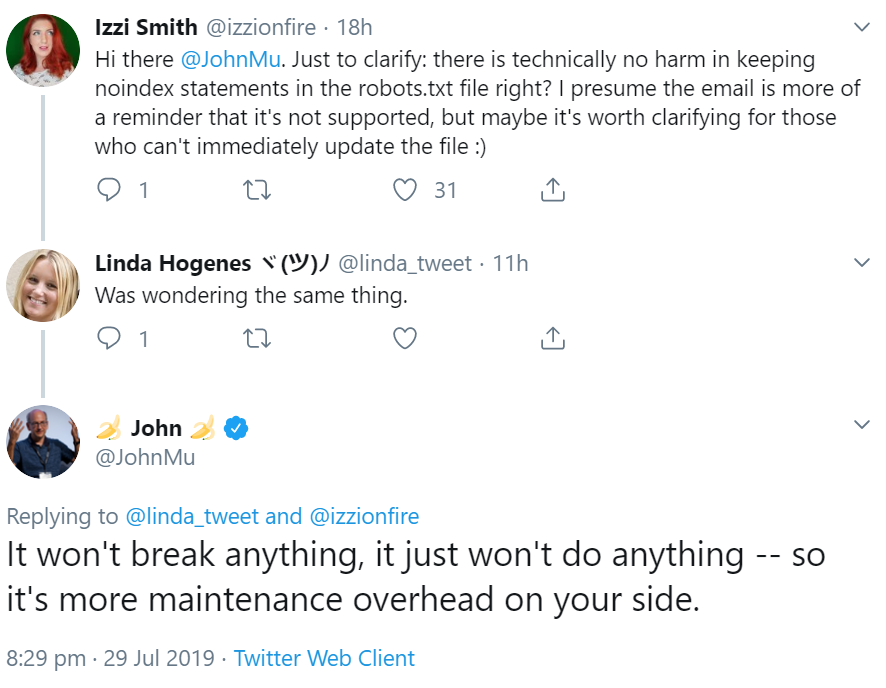
Wer URLs von der Indexierung ausschließen möchte, sollte das entweder unter Verwendung der Meta Robots Tags im HTML oder durch Einsatz des X-Robots-Tags im HTTP-Header tun. Die robots.txt dagegen dient nur der Steuerung des Crawlens: Damit kann mitgeteilt werden, welche URLs und Pfade die Crawler der Suchmaschinen besuchen dürfen und welche nicht.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
