
Google Shopping: Strukturierte Daten per JavaScript sind keine gute Idee
Google Shopping kann mit strukturierten Daten, die per JavaScript erzeugt werden, wenig anfangen. Das ist ein Unterschied zur normalen Google Suche.
![]() Yahoo stellt seinen Crawler Anthelion als Open Source-Projekt unter Apache zur Verfügung. Anthelion kann in HTML eingebettete strukturierte Daten erkennen und Seiten mit strukturierten Daten bevorzugt besuchen und funktioniert als Plugin des Crawlers Apache Nutch.
Yahoo stellt seinen Crawler Anthelion als Open Source-Projekt unter Apache zur Verfügung. Anthelion kann in HTML eingebettete strukturierte Daten erkennen und Seiten mit strukturierten Daten bevorzugt besuchen und funktioniert als Plugin des Crawlers Apache Nutch.
Strukturierte Daten sind für Suchmaschinen ein wichtiges Hilfsmittel, Inhalte von Webseiten und anderen Dokumenten zu verstehen und zu interpretieren. Die Daten unterstützen erstens die verwendeten Algorithmen bei der Klassifizierung von Webseiten und sparen zweitens Rechenkapazitäten.
Yahoo hat jetzt seinen Crawler für die Erfassung von strukturierten Daten in Webseiten offengelegt und stellt ihn als Open Source-Projekt unter Apache zur Verfügung. Der Name des Projekts lautet Anthelion und leitet sich vom griechischen "gegenüber der Sonne" ab. Er beschreibt eine optische Täuschung, bei der eine weiße, horizontale Linie gegenüber der Sonne sichtbar ist.
Anthelion ist ein Plugin für den Crawler Apache Nutch und erweitert bestimmte Klassen des Projekts. Das Anthelion-Plugin enthält diese Erweiterungen:
Der Crawling-Prozess unter Verwendung von Apache Nutch mit Anthelion sieht so aus: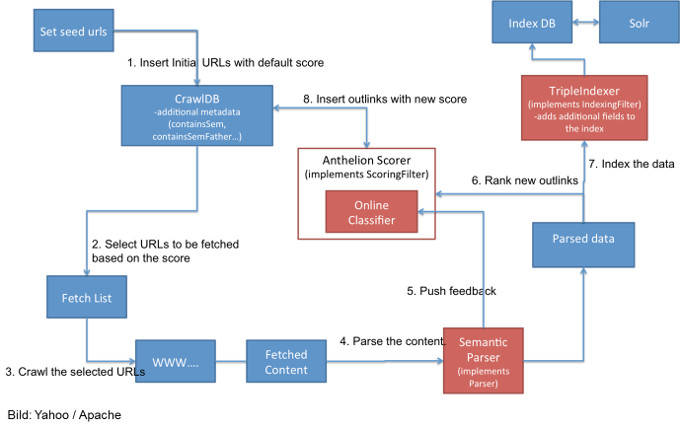
Die roten Felder kennzeichnen die gegenüber dem Crawling mit Nutch angepassten Prozesse.
Bei Anthelion handelt es sich um einen sogenannten Fokussierten Crawler (Focused Crawler). Im Gegensatz zu anderen Crawlern dieser Kategorie ist Anthelion jedoch nicht auf ein bestimmtes Thema ausgerichtet, sondern blickt auf die Daten der Webseiten: Webseiten, die strukturierte Daten enthalten, verfügen über bestimmte Eigenschaften, die Anthelion erkennen kann.
Anthelion grenzt sich außerdem von semantischen Crawlern wie Slug oder LDSpider ab, die für bestimmte Aufgaben im Zusammenhang mit RDF-Daten ausgelegt sind (verschiedene RDF-Formate, Kommunikationsprotokolle etc.). Anthelion ist klar auf die strukturierten Daten ausgelegt, die in das HTML von Webseiten eingebettet sind.
Während des Crawlens lernt Anthelion dazu: Daten, die beim Crawlen gefunden werden, fließen in einen Online-Klassifikator ein. In einem Test hat sich gezeigt, dass Anthelion einen sehr viel größeren Anteil von Webseiten mit strukturierten Daten zurückliefert als ein normaler Crawler: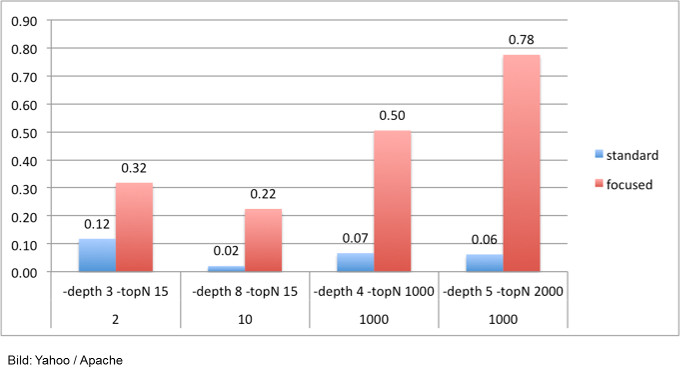
Bild "Architektur" und "Precision": Apache 2.0-Lizenz
Bei einer gewählten Linktiefe von 5 lag die Precision (der Anteil von relevanten zu nicht relevanten Treffern in der Ergebnismenge, also von Seiten mit strukturierten Daten vs. Seiten ohne diese Daten) bei 0,78. Zum Vergleich: Der Standard-Crawler schaffte gerade einmal eine Precision von 0,06.
Anthelion arbeitet mit Apache Nutch 1.6 zusammen. Nutch 1.x und Nutch 2.x sind derzeit noch zwei voneinander unabhängige Projekte. Ob Anthelion auch mit Nutch 2.x funktioniert, ist offen.
Weitere Informationen zu Anthelion gibt es in diesem PDF.




Premium-Partner (Anzeige)

Anzeigen









![]()

![]()
![]()
![]()
