

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.

Damit Google eine Website crawlen kann, muss der Webserver die richtige HTTP-Antwort an den Googlebot senden. Ansonsten kann es zu Problemen kommen.

Beim Crawlen einer Website durch Google spielen verschiedene Faktoren eine Rolle, die auch zu Problemen führen können. Dazu gehört zum Beispiel die robots.txt und mit ihr möglicherweise blockierte URLs und Verzeichnisse. Wichtig ist aber auch, dass der Webserver beim Abruf von Seiten durch den Googlebot die richtige HTTP-Antwort sendet. Passiert das nicht, kann Google die Website nicht crawlen.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Von einem solchen Probklem berichtete John Müller auf LinkedIn. Dabei ging es um eine Website, deren mobile Version nicht vom Googlebot abgerufen werden konnte, weil der Webserver jeweils den HTTP-Status 418 sendete. Dieser HTTP-Status steht für "I'am a teapot". Er wird von manchen Websites gesendet, um automatische Abrufe zu unterbinden.
Müller schrieb, technisch gesehen sei es Cloaking, dem Googlebot einen anderen HTTP-Status als den Nutzern zu senden. Praktisch würde das dazu führen, dass das Crawlen und Indexieren der Website nicht möglich seien. Im konkreten Beispiel führt das dazu, dass die mobile Version der Webseite von Google bis heute nicht indexiert wurde.
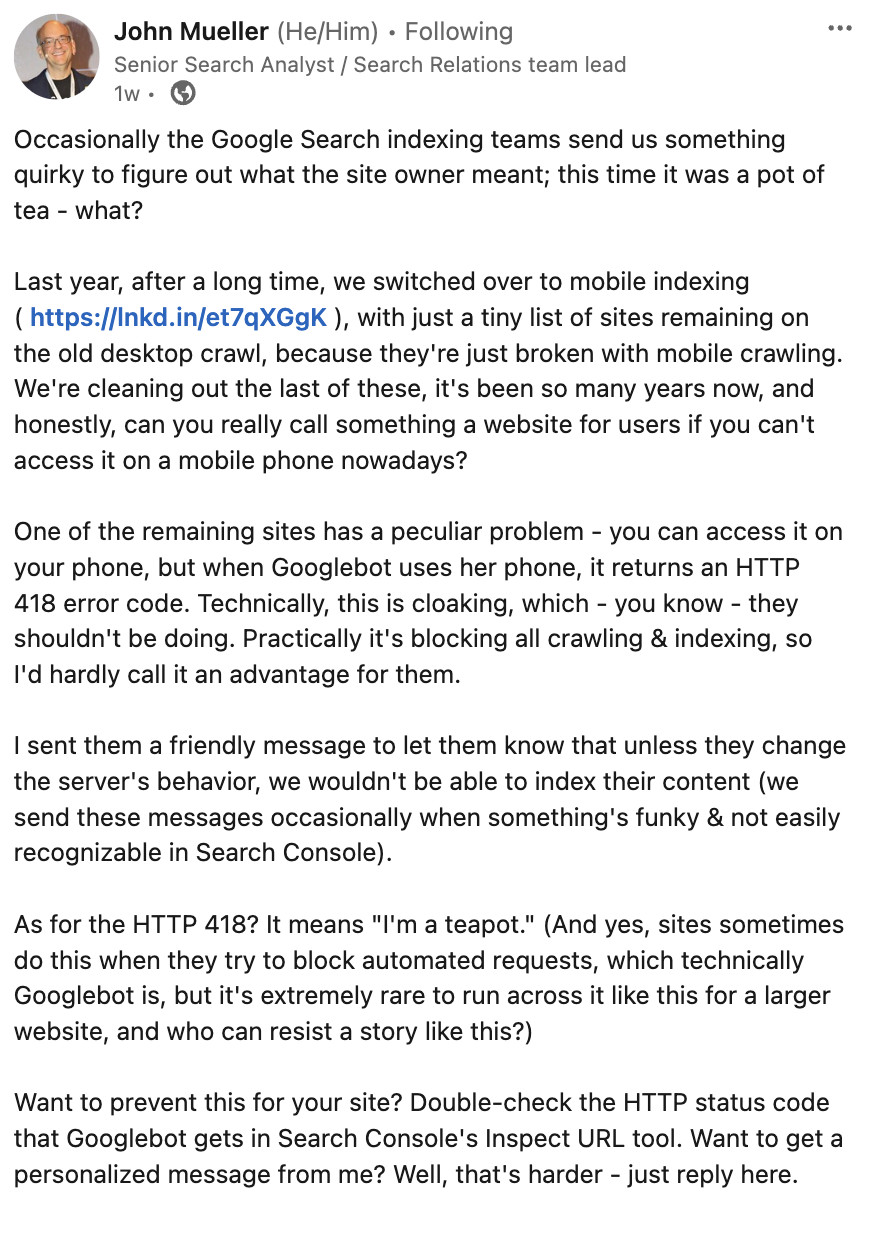
Müller empfahl, den HTTP-Status von URLs für den Googlebot per URL Inspection Tool in der Google Search Console zu prüfen. Außerdem sollte man auch regelmäßig die Crawling-Statistiken in der Google Search Console im Blick behalten.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
