 Webseiten, die auf Googles Framework AngularJS basieren, stellen besondere Anforderungen an die Fähigkeiten der Suchmaschinen und damit auch der SEOs. Eine fehlerhafte Implementierung kann dazu führen, dass das Crawlen und Indexieren durch die Suchmaschinen scheitert. Nun gibt es Gerüchte, dass Google Erweiterungen für die Behandlung von Angular JS-Webseiten planen könnte.
Webseiten, die auf Googles Framework AngularJS basieren, stellen besondere Anforderungen an die Fähigkeiten der Suchmaschinen und damit auch der SEOs. Eine fehlerhafte Implementierung kann dazu führen, dass das Crawlen und Indexieren durch die Suchmaschinen scheitert. Nun gibt es Gerüchte, dass Google Erweiterungen für die Behandlung von Angular JS-Webseiten planen könnte.
Inhalte per AnguarJS für Crawler schwer zu verstehen
Zunächst einige Hintergrundinformationen zu AngularJS: Es handelt sich dabei um ein Framework für Webseiten oder viel mehr von Web-Applikationen. Hauptbestandteil solcher Webseiten bzw. Web-Applikationen sind dynamische Inhalte, die ohne ein erneutes Laden der Seite ausgespielt werden können. Dazu kommt Javascript zum Einsatz. Der Aufbau der Seiten findet auf dem Client und nicht auf dem Server statt.
Das genau kann beim Crawlen und Indexieren durch die Suchmaschinen jedoch zum Problem werden, denn im Quellcode, der vom Server ausgeliefert wird, befindet sich oft nicht viel mehr als ein Aufruf wie dieser: <div ng-view></div>
Mittels einer solchen "Binding-Direktive" wird AngularJS dann erst angewiesen, das Document Object Model (kurz DOM) der Webseite zu manipulieren und damit die Seite aufzubauen. Die Crawler der Suchmaschinen bekommen davon allerdings nichts mit - sie sehen nur die Anweisungen im ursprünglichen Quellcode.
Um Seiten, die unter AngularJS laufen, dennoch crawlbar zu machen, kann man sich einer Hilfslösung bedienen: Per speziellem Request wird der Server angewiesen, einen HTML-Snapshot aufzurufen. Dazu muss die entsprechende URL zusammen mit einem bestimmten Parameter aufgerufen werden: ?_escaped_fragment_
Dieser Parameter zeigt dem Server, dass er nicht die normale Version der Webseite ausliefern soll (die dann per AngularJS auf dem Client aufgebaut wird), sondern eben eine fertige HTML-Version, die der Crawler verstehen kann. So würde zum Beispiel der Aufruf http://beispielseite.de/?_escaped_fragment_=/kategorie/produktseite1 die Seite "/kategorie/produktseite1" als HTML-Snapshot aufrufen.
Google erklärt das entsprechende Zusammenspiel für den Aufruf von dynamischen Webseiten anhand dieser Grafik: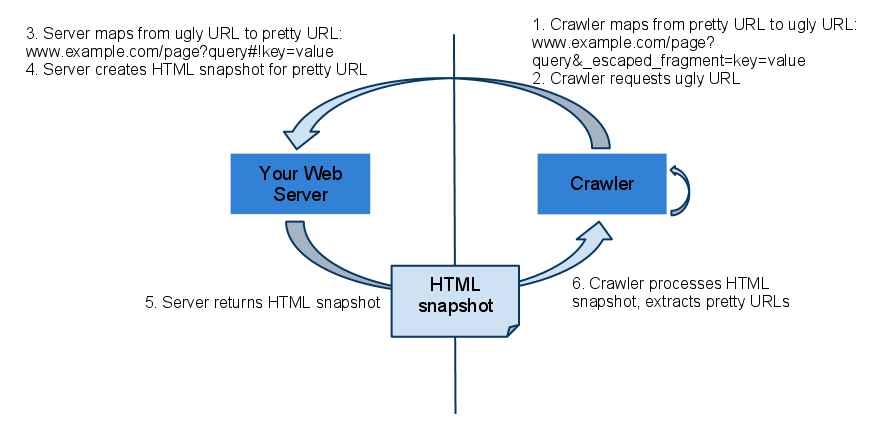
Zunächst ermittelt der Crawler die so genannte "Ugly URL", dier er im zweiten Schritt vom Server anfragt. Der Server liefert auf Basis dieser URL einen HTML-Snapshot der Seite, die der Crawler verarbeitet und die "Ugly-URLs" durch die Original-URLs der Seite ersetzt.
Erweiterung der Möglichkeiten für das Crawlen von AngularJS
Bis zu diesem Punkt ist das nichts Neues, doch könnte sich bei der Indexierung von Webseiten, die unter AngularJS laufen, bald etwas ändern. Es sieht so aus, als suche Google nach neuen Möglichkeiten, solche Seiten crawlen und indexieren zu können. Darauf deutet ein Post von Googles Gary Illyes hin, der sowohl auf Twitter als auch auf Google+ angefragt hat, ob es bereits Webseiten auf Basis von Angular JS gibt, die ohne Parameter ?_escaped_fragment_= auskommen:
Can you ping me if you are using Angular JS on your site, without escaped_fragment?
Daraufhin gab es einige positive Reaktionen - so sollen zum Beispiel die Seiten lastminute.com/entertainment oder globalpost.com ohne den Parameter indexierbar sein.
Fazit
Für Google wäre es in mehrfacher Hinsicht vorteilhaft, die Möglichkeiten zur Indexierung von AngularJS-Seiten zu erweitern: Erstens würde davon das eigene Framework profitieren, und zweitens könnten sich dadurch Einsparungen bei den für das Crawlen und Indexieren notwendigen Ressourcen ergeben. Man darf gespannt sein, wie es in dieser Sache weitergehen wird.
Weitere Informationen
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















