
KI-Bots: Google rät von zusätzlichen Content-Direktiven in robots.txt ab
John Müller von Google rät von zusätzlichen Content-Direktiven in der robots.txt ab, die zur Steuerung von KI-Bots verwendet werden sollen.
 Google berücksichtigt eine robots.txt-Datei nur dann, wenn sie sich im Wurzelverzeichnis der Webseite befindet. Auch das Sperren von Unterverzeichnissen sollte vom Wurzelverzeichnis ausgehend erfolgen.
Google berücksichtigt eine robots.txt-Datei nur dann, wenn sie sich im Wurzelverzeichnis der Webseite befindet. Auch das Sperren von Unterverzeichnissen sollte vom Wurzelverzeichnis ausgehend erfolgen.
Per robots.txt kann definiert werden, welche Dateien und Pfade auf einem Webserver von den Crawlern der Suchmaschinen besucht und welche ausgeschlossen werden sollen.
Google berücksichtigt eine robots.txt allerdings nur, wenn sie sich im Wurzelverzeichnis einer Webseite befindet. Das hat John Müller auf Anfrage bestätigt. Zuvor hatte ein Nutzer per Twitter mitgeteilt, dass er in seinen Logfiles Aufrufe des Googlebots auf robots.txt-Dateien in verschiedenen Unterordnern gesehen hätte. Laut Müller seien diese Aufrufe vermutlich durch gesetzte Links entstanden. Normales Crawling komme als Ursache nicht in Frage. Google berücksichtige eine robots.txt nur, wenn sie sich im Root-Verzeichnis befinde.
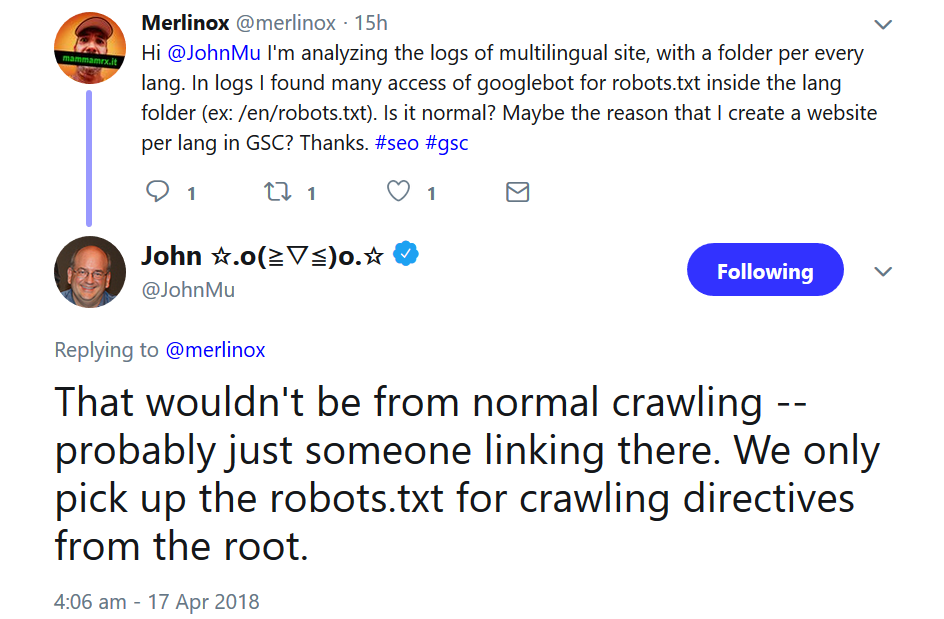
Auch Unterverzeichnisse sollten also über die robots.txt im Wurzelverzeichnis verwaltet werden, damit Google die Anweisungen befolgen kann. Um ein bestimmtes Unterverzeichnis zu sperren, kann man eine Direktive wie die folgende verwenden:
User-agent: *
Disallow: /verzeichnis/
Titelbild: Google


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
