Es gibt einen grundlegenden Unterschied in der Art und Weise, wie Google JavaScript-Webseiten indexiert. Wegen der hohen dazu benötigten Rechenleistung kann es sein, dass solche Inhalte erst nach mehreren Tagen komplett indexiert werden.
Es gibt einen grundlegenden Unterschied in der Art und Weise, wie Google JavaScript-Webseiten indexiert. Wegen der hohen dazu benötigten Rechenleistung kann es sein, dass solche Inhalte erst nach mehreren Tagen komplett indexiert werden.
Google ist inzwischen dazu in der Lage, JavaScript auszuführen und zu interpretieren. Was aber jetzt im Rahmen der Google I/O bekannt wurde, dürfte die meisten Webmaster und SEOs überraschen: Bei JavaScript-Webseiten können zwischen dem erstmaligen Crawlen und der kompletten Indexierung durch Google mehrere Tage vergehen. Der Grund dafür sind Ressourcenprobleme.
Weil das Ausführen von JavaScript vergleichsweise viel Rechenleistung erfordert, agiert Google bei solchen Seiten in meheren Schritten oder Wellen. Zunächst einmal werden die serverseitig gerenderten Inhalte abgerufen, gefolgt von einer initialen Indexierung. Erst dann, wenn genügend freie Rechenkapazitäten zur Verfügung stehen, werden der clientseitige Code interpretiert und weitere Inhalte indexiert. So kann es also sein, dass eine Seite bereits in den Index wandert, obwohl ihre Inhalte noch nicht vollständig von Google erfasst wurden, was manchmal erst Tage später geschehen kann. Durch diesen mehrstufigen Prozess können also zunächst Lücken entstehen.
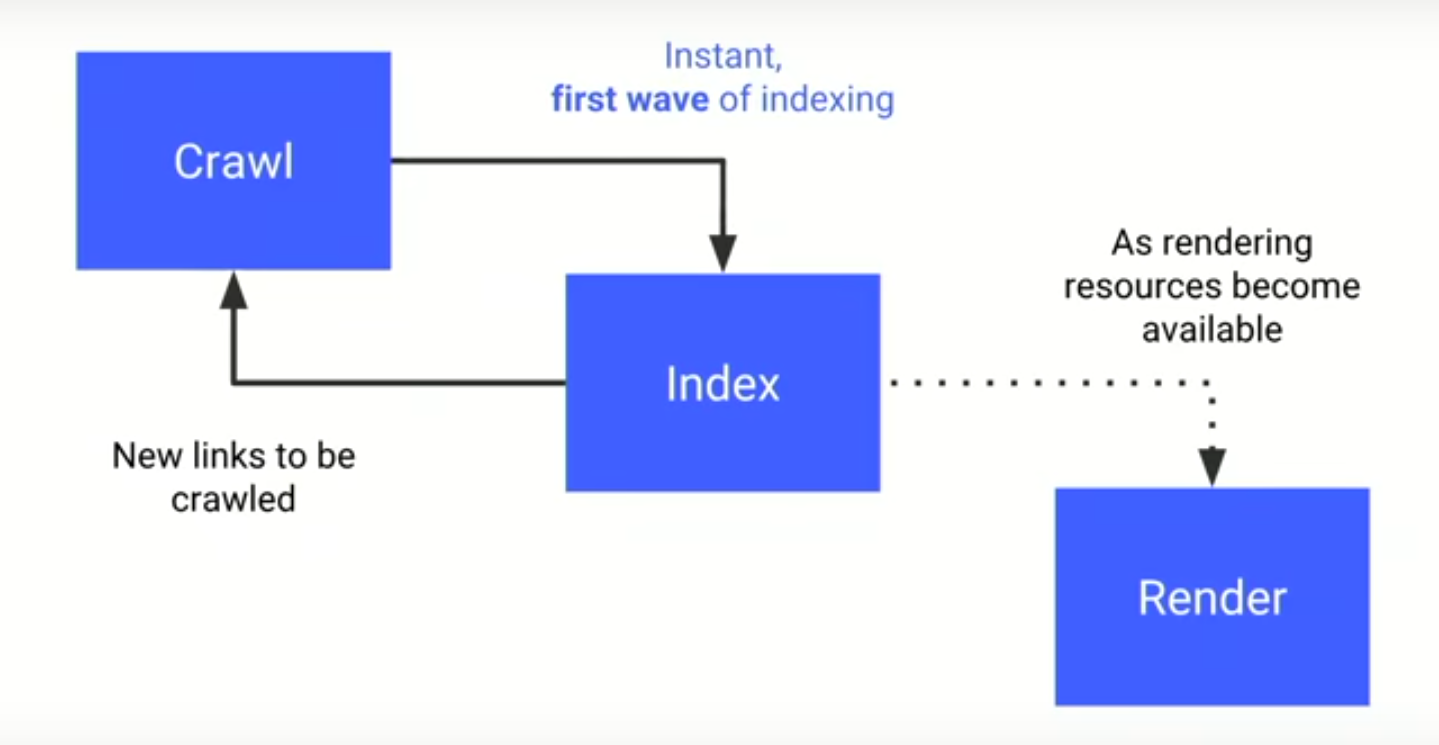
Das kann vor allem für solche Seiten zum Problem werden, die sehr auf Aktualität ausgelegt sind, wie zum Beispiel Nachrichtenportale. Ein weiterer Effekt ist eine dadurch verursachte Volatilität der indexierten Inhalte, was zur Verwirrung der betroffenen Webmaster führen kann.
Daraus kann für Webmaster, denen an einer schnellen Indexierung ihrer Inhalte gelegen ist, nur die Empfehlung abgeleitet werden, die betreffenden Inhalte als statisches HTML auszuliefern.
Titelbild: Google
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige