
KI-Bots: Google rät von zusätzlichen Content-Direktiven in robots.txt ab
John Müller von Google rät von zusätzlichen Content-Direktiven in der robots.txt ab, die zur Steuerung von KI-Bots verwendet werden sollen.
 Google indexiert auch Seiten, die per robotx.txt für das Crawlen gesperrt sind. Voraussetzung ist, dass Links auf diese Seiten zeigen.
Google indexiert auch Seiten, die per robotx.txt für das Crawlen gesperrt sind. Voraussetzung ist, dass Links auf diese Seiten zeigen.
Das Sperren per robots.txt ist keine Garantie dafür, dass Google eine Seite nicht indexiert. Zwar bewirkt ein "disallow" in der robots.txt, dass Google eine Seite nicht crawlt, aber die Indexierung ist dennoch möglich. Das geschieht, wenn es Links gibt, die auf die betreffende Seite zeigen, wie Johannes Müller im Webmaster-Hangout vom 22. März erklärte.
Weil Google diese Seiten aber nicht crawlen kann, verwendet die Suchmaschine Informationen aus den verweisenden Links wie zum Beispiel den Titel. Seiten, die auf diese Weise indexiert werden, erscheinen allerdings nur selten in den Suchergebnissen, wie Müller erklärte. Das liege daran, dass Google durch das fehlende Crawlen zu wenige Informationen über die Seiten besitze, um zu entscheiden, wann diese relevant für eine Suchanfrage seien.
Anders sei es, wenn die Homepage oder eine komplette Website per "disavow" gesperrt sei. Diese werde von Google trotzdem so lange in den Suchergebnissen angezeigt, bis es sicher sei, dass die Seite nicht mehr bestehe.
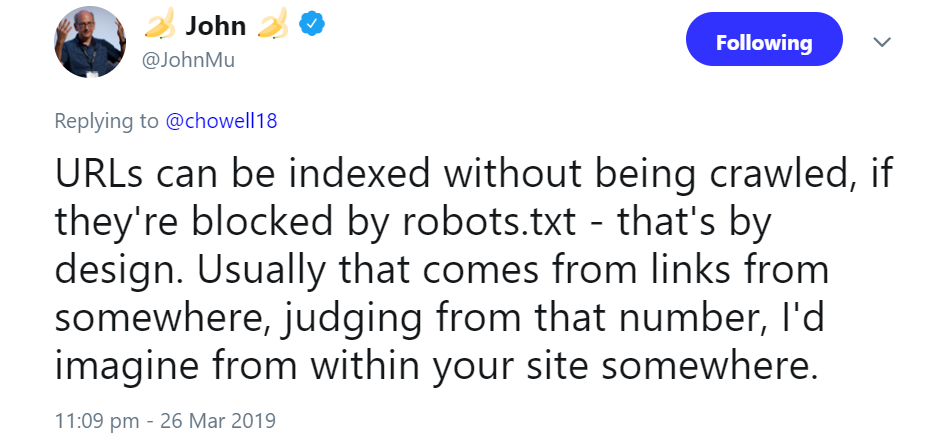
Übrigens können auch interne Links dazu führen, dass Google Seiten indexiert, die per robots.txt gesperrt sind:
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
