

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
 Google crawlt auch per JavaScript erzeugte URLs. Das kann unter Umständen zu einer großen Anzahl zu crawlender URLs führen.
Google crawlt auch per JavaScript erzeugte URLs. Das kann unter Umständen zu einer großen Anzahl zu crawlender URLs führen.


Google nutzt viele verschiedene Quellen, um zu crawlende URLs zu finden. Dazu gehören neben Links auch URLs in Sitemaps und sogar URLs im Text, die nicht verlinkt sind.
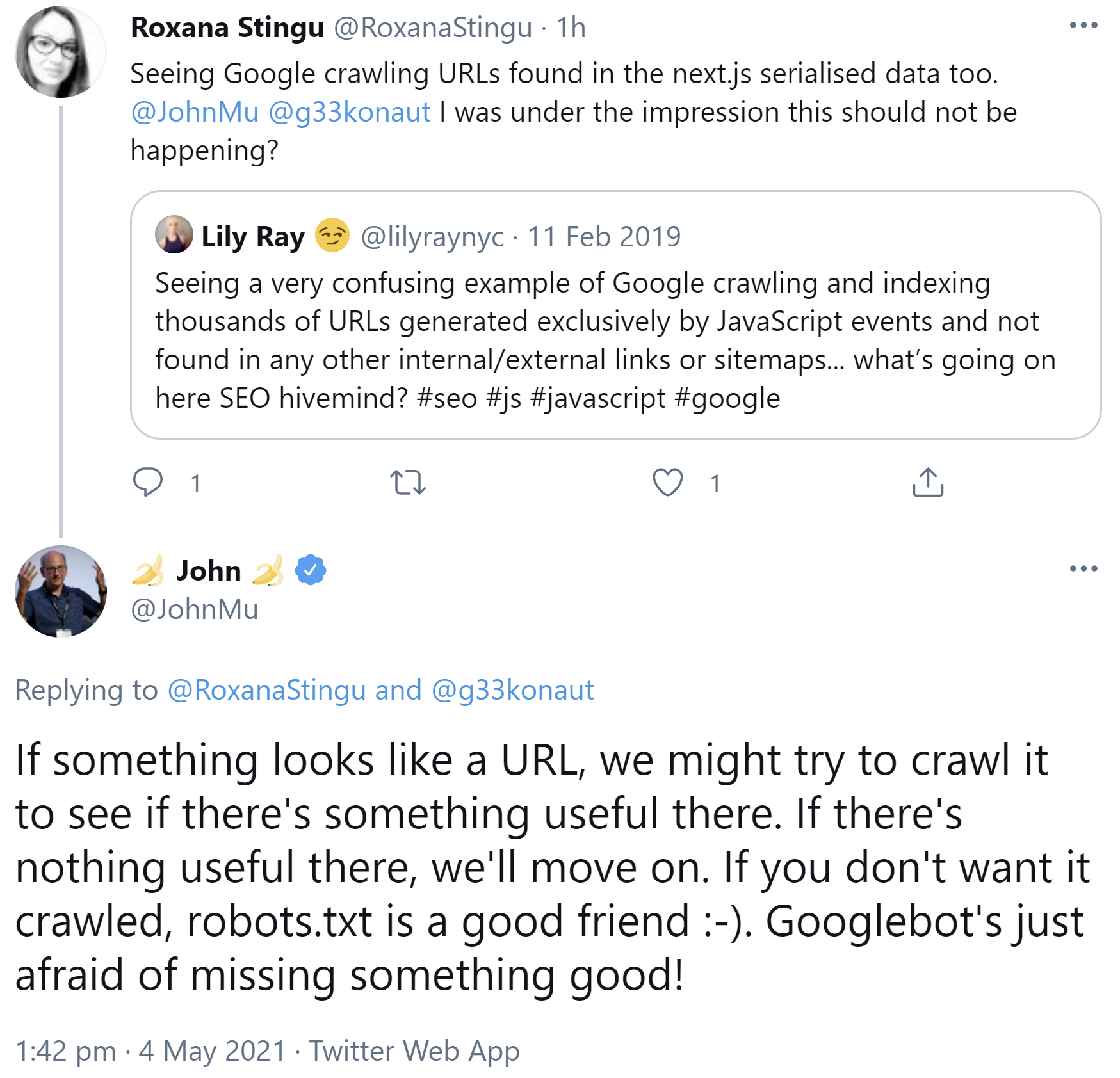
Auch per JavaScript erzeugte URLs können vom Googlebot besucht werden. John Müller schrieb auf Twitter, wenn etwas wie eine URL aussehe, dann versuche Google, es zu crawlen. Gebe es dort nichts Sinnvolles, dann ziehe Google weiter. Wenn man URLs vom Crawlen ausschließen möchte, dann sei die robots.txt die erste Wahl.
Müller schrieb dies als Antwort auf mehrere Tweets, in denen beschrieben wurde, dass Google mehrere per JavaScript erzeugte URLs gecrawlt habe - zum Beispiel in serialisierten Daten oder aus JavaScript-Events:
"If something looks like a URL, we might try to crawl it to see if there's something useful there. If there's nothing useful there, we'll move on. If you don't want it crawled, robots.txt is a good friend :-). Googlebot's just afraid of missing something good!"
Werden auf einer Website also potentiell viele URLs per JavaScript erzeugt, sollte man diese im Zweifelsfall per robots.txt sperren - es sei denn, es ist ausdrücklich erwünscht, dass Google diese crawlt.




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
