

75 Prozent der Websites, die KI-Bots blockieren, tauchen dennoch in KI-Zitaten auf
Das Blockieren von KI-Bots verhindert in den meisten Fällen nicht, dass die betreffenden Inhalte von der KI zitiert werden.

Nach einem Bericht von Cloudflare verbirgt Perplexity seine Identität und crawlt Websites, obwohl dies nach den Vorgaben nicht zulässig wäre.


Eigentlich sollte Perplexity die Vorgaben der robots.txt respektieren. So zumindest hatte es das Unternehmen erklärt. Nun sieht es aber danach aus, als umgehe Perplexity die Direktiven von Websites und crawle diese, und das auch noch mithilfe von verdeckten Crawlern. Das zumindest wird in einem Bericht von Cloudflare behauptet. Dabei soll Perplexity die Identität (ASN) und ihren User Agent verändert, um die Crawling-Aktivitäten zu verschleiern. Manchmal werde dabei die robots.txt ignoriert oder gar nicht erst abgerufen.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Auslöser für die Befunde waren Berichte von Nutzern, die ihre robots.txt und teilweise auch ihre Firewall konfiguriert hatten, um die Crawler von Perplexity, PerplexityBot und Perplexity-User auszuschließen. Obwohl diese Crawler erfolgreich blockiert waren, konnte Perplexity dennoch Inhalte ihrer Websites crawlen.
In einem Experiment mit neu aufgesetzten Domains bestätigte sich der Verdacht: Trotz Vorkehrungen gegen das Crawlen konnte Perplexity Fragen zum Inhalt der Websites beantworten. Perplexity nutzte nicht nur den offiziellen User Agent, sondern agierte auch mit einer Tarnung. Dort gab sich Perplexity als Google Chrome auf MacOS aus.
|
Offiziell |
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user) |
20-25m tägliche Abfragen |
|
Tarnung |
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 |
3-6m tägliche Abfragen |
Dabei nutzte Perplexity rotierende IP-Adressen, die sich nicht auf der offiziellen Liste der IP-Range von Perplexity befinden. Zudem wurden Abfragen von verschiedenen ASNs durchgeführt, offenbar, um Sperren auf Websites zu umgehen. Dabei seien Zehntausende von Domains mit Millionen von Abfragen betroffen gewesen.
Die Umgehung der Sperren zeigt die folgende Abbildung:
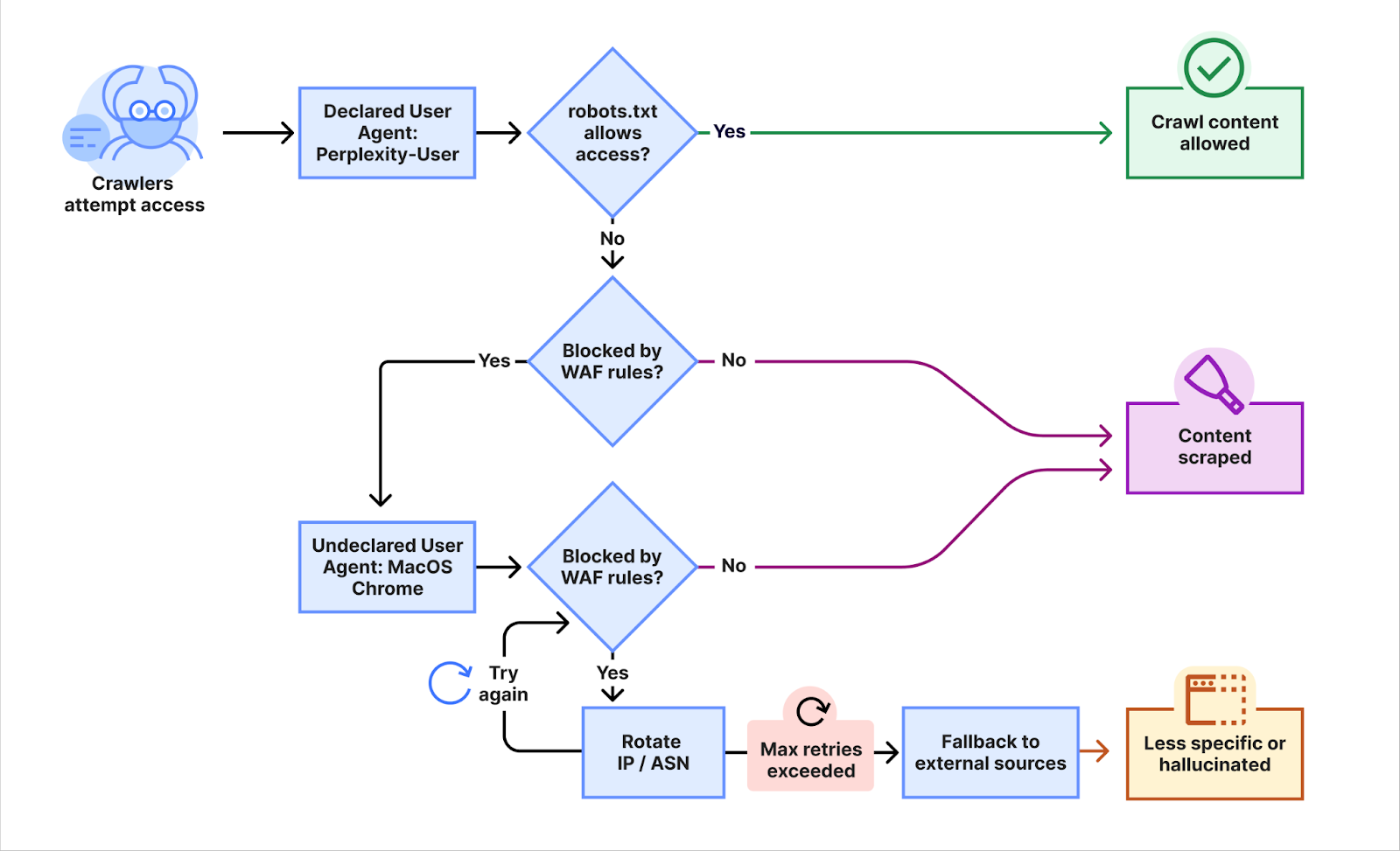
Um das ungewünschte Crawlen von Inhalten durch Perplpexity zu verhindern, kann man laut Cloudflare entsprechende Regeln im CDN nutzen, die so erweitert wurden, dass die die betreffenden Zugriffe verhindern.
Die für ChatGPT genutzten Crawler von OpenAI halten sich laut Cloudflare übrigens an die Vorgaben der robots.txt und versuchen nicht, diese zu umgehen.

{loadoposition anzeige-unter-newsletter}



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
