
Google: warum es keine Rolle spielt, wann eine Domain registriert wurde
Für die Rankings in den Google-Ergebnissen ist es unerheblich, wann eine Domain registriert wurde. Google erklärt, warum das so ist.
 Google hält sich meist bedeckt, was die Funktionsweise der Suche betrifft. Welche Faktoren das Ranking beeinflussen, wie stark der Einfluss der verschiedenen Rankingfaktoren ist und nach welchen Gesichtspunkten Google bestimmte Webseiten favorisiert, darüber kann nur spekuliert werden. Wer es etwas genauer wissen möchte, dem sei ein Blick auf Googles Enterprise-Suche mit dem Namen Google Search Appliance (GSA) empfohlen. Unternehmen können sich einen Suche-Server von Google in ihrem Rechenzentrum installieren und eine eigene, kleine Suchmaschine aufsetzen. Der Vorteil der GSA: Die Dokumentation beschreibt recht genau, wie die Suche funktioniert und welche Faktoren das Crawlen beeinflussen. Auch zum Ranking gibt es wertvolle Hinweise.
Google hält sich meist bedeckt, was die Funktionsweise der Suche betrifft. Welche Faktoren das Ranking beeinflussen, wie stark der Einfluss der verschiedenen Rankingfaktoren ist und nach welchen Gesichtspunkten Google bestimmte Webseiten favorisiert, darüber kann nur spekuliert werden. Wer es etwas genauer wissen möchte, dem sei ein Blick auf Googles Enterprise-Suche mit dem Namen Google Search Appliance (GSA) empfohlen. Unternehmen können sich einen Suche-Server von Google in ihrem Rechenzentrum installieren und eine eigene, kleine Suchmaschine aufsetzen. Der Vorteil der GSA: Die Dokumentation beschreibt recht genau, wie die Suche funktioniert und welche Faktoren das Crawlen beeinflussen. Auch zum Ranking gibt es wertvolle Hinweise.
Die Google Search Appliance (GSA) liegt inzwischen in der Version 7.4 vor. Sie basiert auf Dell-Hardware und nutzt als Betriebssystem CentOS. Je nach Lizenz lassen sich per GSA bis zu 100 Millionen Dokumente indexieren. Viele Unternehmen nutzen GSA, um zum Beispiel ihr Intranet oder ihren Produktbestand durchsuchbar zu machen.
GSA ist recht einfach zu installieren und funktioniert fast komplett per „Plug & Play“. Sie bietet einen mächtigen Funktionsumfang und lässt sich an die Bedürfnisse des Kunden anpassen. Neben der Gestaltung individueller Benutzeroberflächen über das Einrichten von Filtern für verschiedene Sprachen, Dateitypen und Domains bis hin zum Beeinflussen der Rankings ist alles möglich.
Die GSA nutzt eine riesige Zahl an Rankingfaktoren – laut Dokumentation gibt es mehr als 100 davon. Wie bei Googles großer Suchmaschine auch werden keine Details zu einzelnen Rankingfaktoren genannt. Einige Hinweise gibt es aber doch: Zunächst einmal kommt es beim Ranking auf die Relevanz der Dokumente für die jeweilige Suchanfrage an. Dabei kommt vermutlich ein TF/IDF-Verfahren zum Einsatz, wie es auch bei anderen Suche-Servern wie zum Beispiel Apache Solr verwendet wird.
TF steht dabei für Term Frequency, IDF für Inverse Document Frequency. Vereinfacht gesagt ist ein Dokument für ein bestimmtes Keyword umso relevanter, desto häufiger dieses Keyword im Dokument vorkommt und desto seltener dieses Keyword in der Gesamtmenge aller Dokumente auftaucht. Seltene Fachbegriffe erhalten auf diese Weise ein stärkeres Gewicht als häufig vorkommende, allgemeine Begriffe.
Zusätzlich verwendet die GSA einen „Enterprise PageRank“. Vom Prinzip her entspricht der Enterprise PageRank dem bekannten PageRank, der auch bei Google selbst zum Einsatz kommt. Er bestimmt sich aus der Verlinkung eines Dokuments im Netz. Umso mehr Links auf ein Dokument zeigen, und je höher der PageRank der Dokumente ist, die auf das betreffende Dokument zeigen, desto höher ist auch der PageRank des Dokuments selbst.
Im Gegensatz zum beschriebenen PageRank beschränkt sich der Enterprise PageRank jedoch auf die Dokumente innerhalb eines geschlossenen Systems, also zum Beispiel des Unternehmens, in dem die GSA zum Einsatz kommt, und die zwischen ihnen bestehenden Beziehungen.
Als weiterer Rankingfaktor in der GSA gibt es einen Mechanismus, der für eine kontinuierliche Verbesserung der Suchergebnisse dienen soll. Dieser Mechanismus trägt den Namen „Automatic Self-Learning Scorer“ und wendet statistische Methoden an, um die Gewichtung der Rankingfaktoren im Hinblick auf die Bedürfnisse der Nutzer zu optimieren. Dabei werden Faktoren ausgeblendet, die zur Verfälschung der Ergebnisse führen könnten, wie zum Beispiel der „Trust Bias“. Darunter versteht man die Tendenz, auf das an erster Position gerankte Suchergebnis zu klicken, unabhängig davon, wie relevant dieses Ergebnis tatsächlich ist.
Rankings in der GSA können nach Belieben beeinflusst werden, um bestimmte Dokumente entweder auf- oder abzuwerten. Sogenannte „Results Biasing Policies“ enthalten entsprechende Regeln, die auf Basis von Sprache, URL, Domain oder Dateityp Ergebnisse manipulieren können.
Besonders interessant wird es, wenn man einen Blick auf das Crawl-Verhalten der GSA wirft und nach welchen Kriterien die URLs zum Crawlen ausgewählt werden.
Die höchste Priorität genießen dabei die Start-URLs, also die URLs, die als „Seeds“ bestimmt wurden. Diese bilden den Ausgangspunkt für das Crawlen der übrigen Dokumente. Sie werden manuell festgelegt.
An nächster Stelle folgen neue URLs, die noch nie zuvor gecrawlt wurden. Diese werden untereinander anhand des geschätzten Enterprise PageRanks priorisiert. Geschätzt wird der PageRank aus dem Grund, dass erst nach dem Crawlen und Indexieren aller Dokumente ein genauer Wert bestimmt werden kann.
Für ein erneutes Crawlen von URLs bestimmt sich die Priorität aus dem Enperprise PageRank sowie einem Faktor, der sicherstellt, dass zunächst alle neuen URLs gecrawlt werden, bevor ein Recrawl bereits indexierter Dokumente stattfindet.
Für bereits im Index befindliche Dokumente findet die Priorisierung ebenfalls auf Basis des Enterprise PageRanks statt. Berücksichtigt wird jedoch auch die vermutete Änderungshäufigkeit der Dokumente.

Aus diesen Angaben lassen sich interessante Vermutungen und Annahmen im Hinblick auf Googles Suchmaschine ableiten. Auch hier kann davon ausgegangen werden, dass vor allem neue, noch nicht indexierte Dokumente mit einer größeren Wahrscheinlichkeit eines Crawler-Besuchs rechnen können, und zwar erst recht dann, wenn sie zu einer Webseite mit hohem PageRank gehören und sich häufiger ändern, wie es zum Beispiel bei Nachrichtenseiten oder gut gepflegten Blogs der Fall ist.
Übrigens hält sich auch der Crawler der GSA an die bekannten Anweisungen wie robots.txt oder Meta-Robots-Attribute. Dieses Verhalten kann man per Konfiguration nach Belieben anpassen.
Interessant ist, dass die GSA auch URLs crawlen kann, die per JavaScript erzeugt werden. Einschränkungen gibt es aber: So müssen die Skripte in das jeweilige, zu crawlende Dokument eingebunden sein. Externe JavaScript-Dateien funktionieren hier also nicht. Auch Referenzen auf das DOM (Document Object Model) per getElementById() funktionieren nicht.
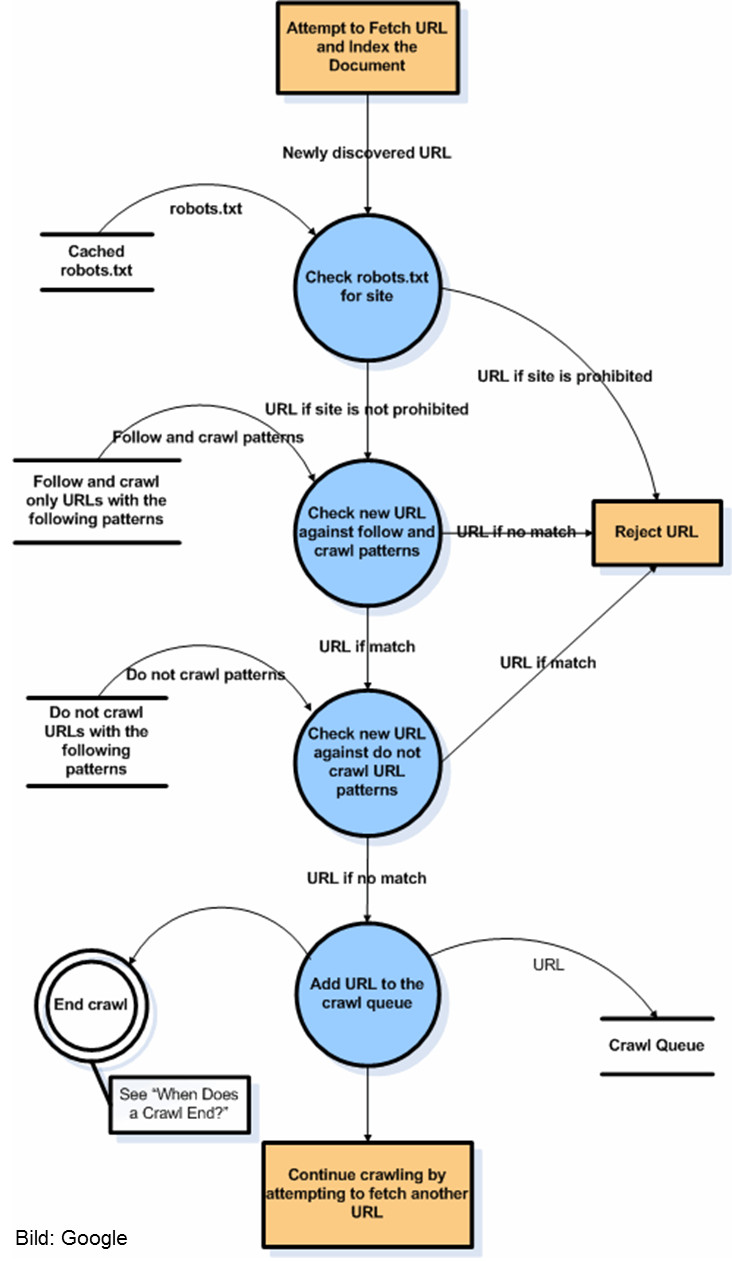
Wie das Ablaufdiagramm zeigt, werden beim Crawlen durch die GSA die verschiedenen Regeln und Direktiven beachtet, die durch robots.txt, Meta-Robots und voreingestellte Crawl- und Do-not-Crawl-Pattern vorgegeben werden. Sobald alle URLs abgearbeitet sind, die sich inklusive der beim Crawlen neu entdeckten URLs in der Crawl-Queue befinden, wird der Vorgang abgeschlossen.
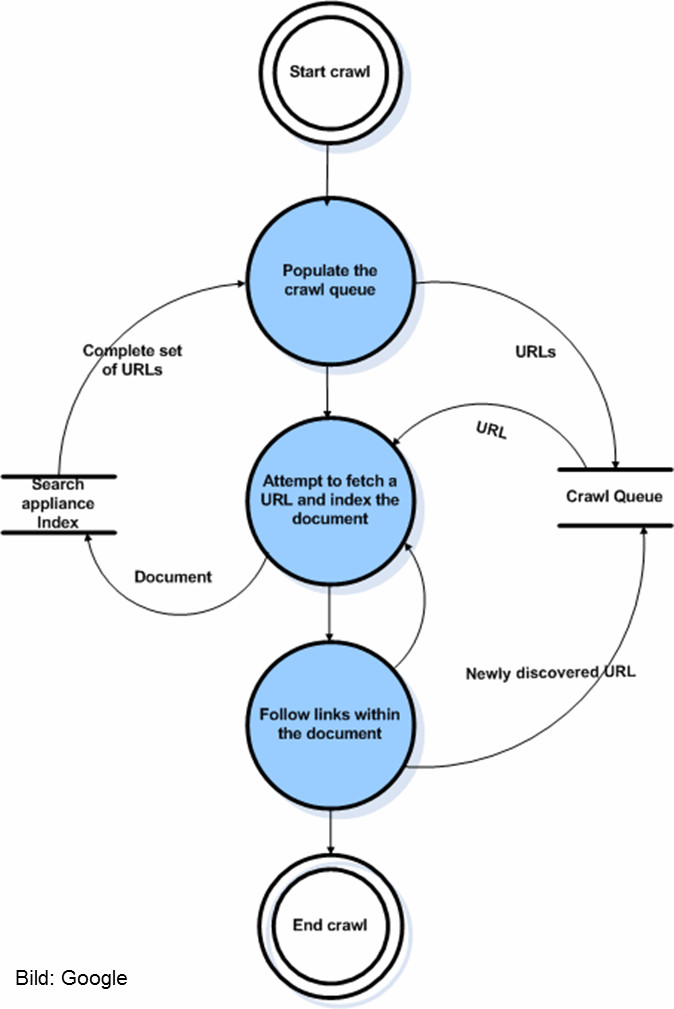
Selbstverständlich funktioniert die GSA nicht in allen Bereichen wie Googles große Suchmaschine. Das kann auch nicht das Ziel sein, denn die Anwendungsfelder sind völlig verschieden. Die GSA dient meist der Durchsuchbarkeit der Dokumente eines Unternehmens oder einer Organisation, während die Web-Suchmaschine Milliarden von Nutzern und Suchanfragen weltweit mit einer unüberschaubaren Menge an Dokumenten versorgen muss.
Was jedoch deutlich wird, sind grundlegende Parallelen in der Funktionsweise zwischen GSA und dem "großen Bruder": Vor allem die Rankingkriterien der GSA und die beschriebenen Verfahren beim Crawlen erlauben Rückschlüsse auf die entsprechenden Prozesse in Googles Suchmaschine. Warum sollte Google auch jeweils völlig unterschiedliche Ansätze verfolgen?
Aus diesem Grund kann es nicht schaden, sich einmal etwas intensiver mit der Dokumentation der GSA zu beschäftigen, die hier zu finden ist.
Titelbild "Google Search Appliance" © Antonio Tajuelo
(Attribution-NonCommercial-NoDerivatives CreativeCommons licenses creativecommons.org/licenses/by/2.0/)


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
