

DeepMind: 50 Prozent Wahrscheinlichkeit für AGI noch in diesem Jahrzehnt
Google DeepMind CEO Demis Hassabis rechnet mit einer 50prozentigen Chance, AGI noch in diesem Jahrzehnt zu erreichen.
 Mit WaveNet hat die Google-Tochter DeepMind ein neues, revolutionäres System zur Sprachausgabe geschaffen. Mit Hilfe maschinellen Lernens kann nicht nur die menschliche Stimme in verblüffender Weise nachgeahmt werden; WaveNet kann auch Musik komponieren und Geräusche erzeugen.
Mit WaveNet hat die Google-Tochter DeepMind ein neues, revolutionäres System zur Sprachausgabe geschaffen. Mit Hilfe maschinellen Lernens kann nicht nur die menschliche Stimme in verblüffender Weise nachgeahmt werden; WaveNet kann auch Musik komponieren und Geräusche erzeugen.
Die Spracherzeugung per Computer, auch Sprachsynthese oder Text-to-Speech (TTS) genannt, geschieht derzeit meist auf Basis eines von zwei Verfahren. Beim ersten Verfahren, der verknüpfenden TTS (Concatenative TTS), werden Sprachschnipsel, die zuvor von einem menschlichen Sprecher generiert und dann aufgenommen wurden, in einer großen Datenbank gespeichert. Zur Sprachausgabe werden diese Sprachscnhipsel dann in der jeweils benötigten Weise wieder kombiniert. Das Problem hierbei besteht in der fehlenden Möglichkeit, Variationen wie unterschiedliche Betonungen oder Stimmungen einzubringen, denn die Schnipsel können nur so verwendet werden, wie sie aufgenommen wurden. Um Varianten zu erzeugen, müssten mehrere Varianten der Sprachschnipsel produziert werden.
Bei der parametrischen TTS werden im Gegensatz zur verknüpfenden TTS alle zur Spracherzeugung benötigten Informationen im Modell selbst abgelegt, das heißt, es ist möglich, durch Veränderung der Parameter Varianten zu erzeugen. Der Nachteil der parametrischen TTS liegt aber in einer meist geringeren Qualität der erzeugten Sprache, die oftmals schwer zu verstehen ist und künstlicher klingt als die mit Hilfe verknüpfender TTS erzeugte Sprache.
Das Londoner Unternehmen DeepMind, eine Google-Tochter, hat mit WaveNet ein neues Verfahren zur Sprachsynthese entwickelt. WaveNet erzeugt Sprache als Wellenform, die sich aus einzelnen Samples zusammensetzt. Dieser Ansatz erlaubt es, nicht nur Sprache, sondern auch Geräusche und Musik auszugeben. Dabei werden sehr viele Samples pro Zeiteinheit erzeugt (16.000 Samples pro Sekunde). Die Berechnung der Samples findet auf Basis eines autoregressiven Modells statt: Jedes Sample wird von allen vorherigen Samples beeinflusst.

Bild: DeepMind
Die obige Grafik illustriert den Ansatz von WaveNet: In einem "gefalteten", mehrschichtigen neuronalen Netz, in dem die verschiedenen Ebenen verschiedene Ausdehnungsfaktoren besitzen, durchläuft der Input verschiedene Ebenen, bis es letztendlich zum Output, dem Sample, kommt.
Im Gegensatz zur Bildanalyse, in der dieses Modell schon länger angewandt wird, reduziert der Ansatz von WaveNet die Komplexität durch die Verwendung von "Hidden Layers", verborgenen Schichten, die es erlauben, Informationen aus der Vergangenheit zu nutzen und somit die Komlexität zu begrenzen.
Ergänzt wird das System durch die Einspeisung zusätzlicher Informationen über den zu sprechenden Text. Dazu wird ein vorliegender Text aufgeteilt in eine Abfolge von sprachlichen und phonetischen Einheiten wie Silben, einzelnen Wörtern usw. Das bedeutet, dass die Vorausberechnung des jeweils nächsten Samples nicht nur auf den vorherigen Samples basiert, sondern auch vom jeweiligen Text abhängt.
Interessanterweise kann WaveNet aber auch ohne die Informationen über den Text etwas wie Sprache erzeugen. Obwohl das Ergebnis vom Klang her sehr vertraut ist, handelt es sich jedoch in diesem Fall nur um ein inhaltsloses Kauderwelsch.
In einem Test mit menschlichen Probanden, bei dem mehr als 500 Bewertungen für 100 Testsätze abgegeben wurden, zeigte sich die Leistungsfähigkeit von WaveNet. Sowohl für die Sprache Englisch als auch für Mandarin-Chinesisch wurde der wahrgenommene Abstand zur menschlichen Sprache als deutlich geringer wahrgenommen als für parametrische oder verknüpfende TTS:
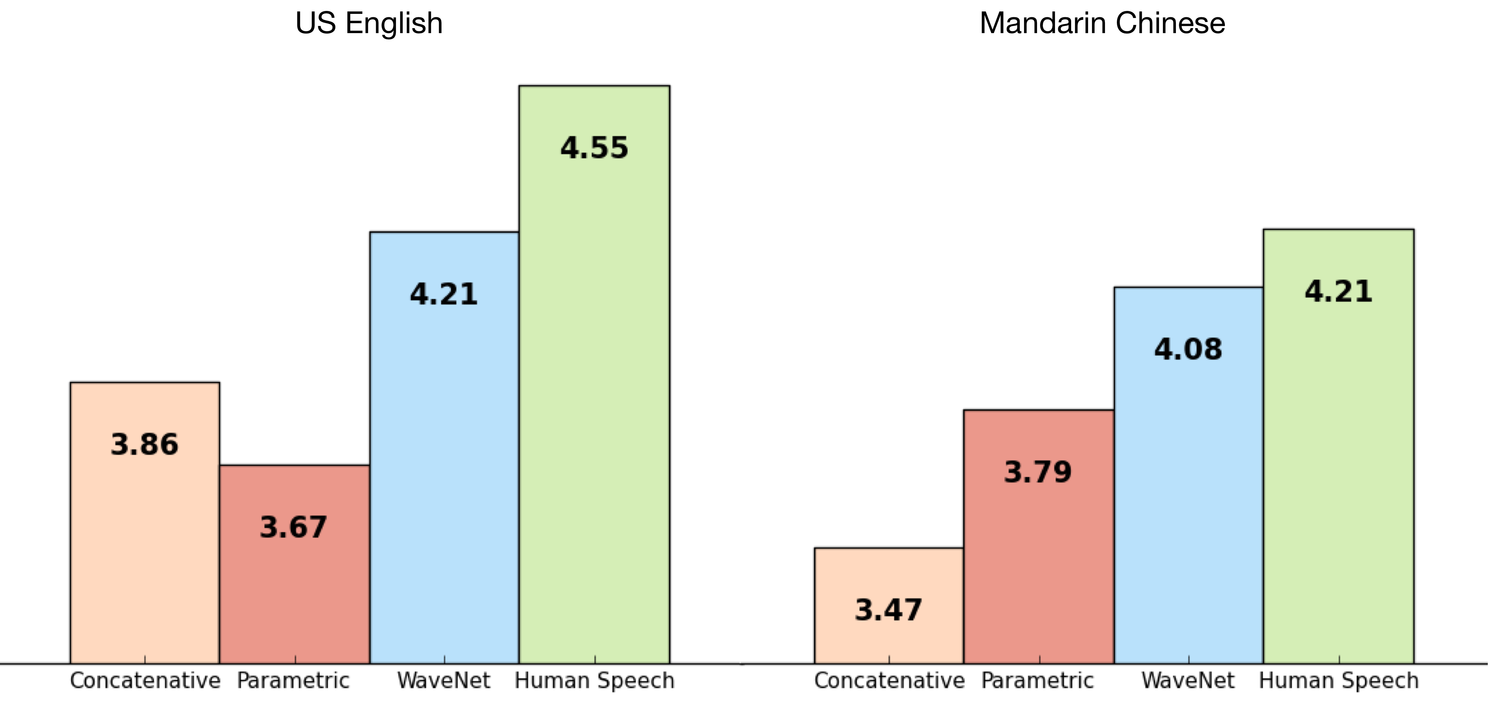
Bild: DeepMind
Als Referenz dienten Googles eigene Systeme zur Spracherzeugung, wie sie derzeit in den Produkten des Unternehmens zum Einsatz kommen.
Wendet man WaveNet anstelle von Sprache auf Musik an, ergeben sich faszinierende Ergebnisse. Im Blogbeitrag von DeepMind sind mehrere Audio-Beispiele verlinkt. Darin sind Klavierkompositionen zu hören, die sich für den Laien nicht von menschlichen Werken unterscheiden. Was mehr als Spaß gedacht war, zeigt die Leistungsfähigkeit von WaveNet: Alleine durch das Trainieren mit einem Datensatz (klassische Klaviermusik) hat das System erstaunliche Ergebnisse produziert.
Was mit Musik funktioniert, lässt sich auch allgemein auf die Ebene von Geräuschen anwenden. Vor allem im Bereich der Sprache kann das zu einer zusätzlichen Annäherung an menschliche Laute führen, wenn zum Beispiel das Atmen mit in die Spracherzeugung einfließt.
Die größte Herausforderung für die Anwendung von WaveNet in der Praxis besteht derzeit im großen Rechenaufwand für die Erzeugung der einzelnen Samples. Sowohl die Rechenkapazitäten in der Google-Cloud als auch die Leistungsfähigkeit aktueller Smartphones stellen hier noch limitierende Faktoren dar. Wenn sich die technischen Bedingungen jedoch so weiterentwickeln wie in der Vergangenheit, dürfte es nicht mehr lange dauern, bis die elektronische Sprachausgabe von der menschlichen kaum noch zu unterscheiden sein wird.
Technische Details zu WaveNet sind in diesem Paper (PDF) zu finden.
Titelbild © AGPhotography - Fotolia.com




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
