

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
 Durch die Verwendung des "noindex"-Attributs können keine Einsparungen für das Crawl-Budget erzielt werden. Wichtig für das Verständnis ist vor allem, zwischen Crawlen und Indexieren zu unterscheiden.
Durch die Verwendung des "noindex"-Attributs können keine Einsparungen für das Crawl-Budget erzielt werden. Wichtig für das Verständnis ist vor allem, zwischen Crawlen und Indexieren zu unterscheiden.
Nur weil man bestimmte Seiten mit dem "noindex"-Attribut versieht, heißt das nicht, dass Google anstelle dieser Seiten andere, zusätzliche Seiten crawlen würde. Das hat Johannes Müller in einer Nachricht auf Twitter bestätigt. Ein Nutzer hatte zuvor gefragt, ob "noindex" Crawl-Budget sparen würde. Die klare Antwort Müllers: "Nein".
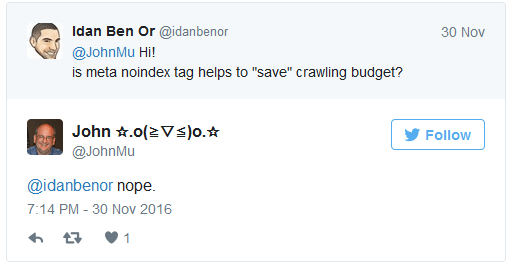
Denkt man einmal über den Crawling-Vorgang nach, ist die Antwort auch sofort nachvollziehbar, denn damit der Crawler erkennen kann, dass eine Seite nicht indexiert werden soll, muss er diese erst einmal besuchen. Dieser Vorgang geht also schon zu Lasten des Crawl-Budgets.
Anders würde es aussehen, wenn eine Seite oder ein ganzer Bereich per robots.txt gesperrt würde: Dann würden die entsprechenden Seiten erst gar nicht vom Crawler besucht und auch nicht indexiert werden. Allerdings kann das nachträgliche Sperren bereits indexierter Seiten per robots.txt dazu führen, dass Google diese im Index belässt, jedoch keine Description mehr für die Seiten anzeigt.
Als Faustregel kann man sich folgendes merken:
Titelbild © AKS - Fotolia.com




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
