 Das Blockieren von 404-Seiten für die Crawler der Suchmaschinen ist laut Google keine gute Idee und kann viele Probleme verursachen.
Das Blockieren von 404-Seiten für die Crawler der Suchmaschinen ist laut Google keine gute Idee und kann viele Probleme verursachen.
Auf fast allen Websites kann es beim Crawlen zu 404-Fehlern kommen. Wenn URLs durch das Löschen oder das Verändern von Seiten oder anderen Ressourcen nicht mehr verfügbar sind, so ist es normal und richtig, dass der Webserver den Status 404 zurückliefert.
Suchmaschinen wie Google können mit 404-Fehlern gut umgehen. Keine gute Idee ist es aber, den Crawlern der Suchmaschinen den Zugriff auf 404-Seiten zu verwähren. Das erklärte jetzt Johannes Müller auf Twitter. Zuvor hatte ein Nutzer erklärt, auf seiner Website seien würden User Agents gesperrt, die mehr als zehn 404-Fehler erhielten. Dazu zähle auch der Googlebot. Es gebe Weiterleitungen dieser Links zu relevanteren Seiten mit mehr passenden Inhalten. Es gebe Hunderte neuer 404er pro Woche.
Müller schrieb, das klinge nach einer sehr schlechten Idee, die verschiedene Probleme verursachen könne. Man könne nicht vermeiden, dass der Googlebot und andere Suchmaschinen auf 404-Seiten stießen. Crawling enthalte auch immer die Möglichkeit, dass URLs, die zuvor noch funktioniert hätten, zu einem 404 führten:
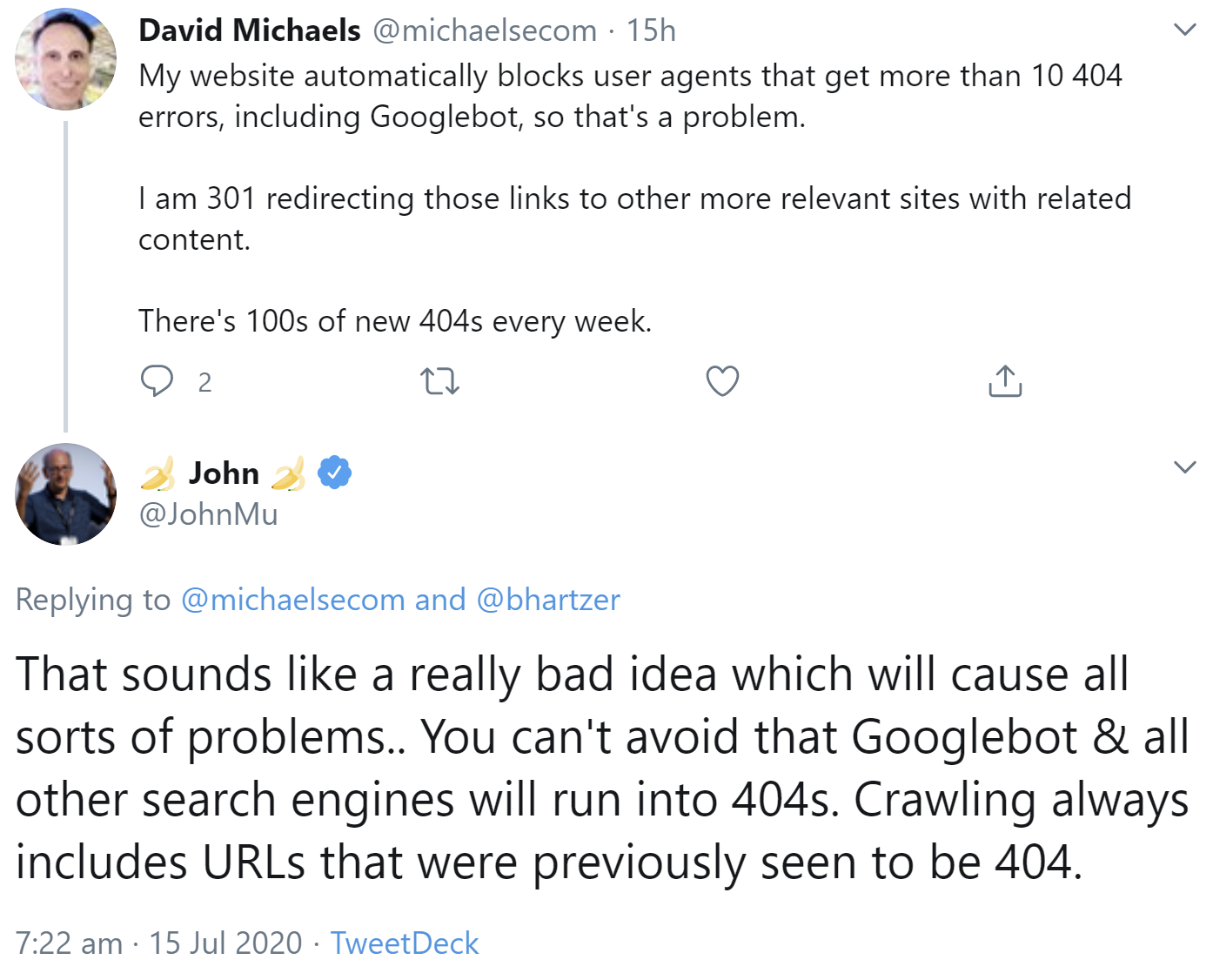
404-Fehler sind ein normaler Bestandteil des Webs. Wenn eine Seite verschoben wird, bietet sich das Einrichten einer Weiterleitung an. Für Seiten, die gelöscht und nicht mehr benötigt werden, ist das Senden des Status 404 die richtige Methode.
Konstrukte wie das oben beschriebene sorgen dagegen nur für unnötige Komplexität mit der Folge, dass Wartung, Pflege und Fehlersuche für eine Website unnötig erschwert werden.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige













