
Technische SEO per KI: Claude Code zeigt, wie es geht
KI bietet im Bereich technische SEO enorme Möglichkeiten. Damit lassen sich selbst Kleinigkeiten erkennen - zum Beispiel falsche Favicons.

Bild KI-generiert
Die technische Suchmaschinenoptimierung oder kurz Technische SEO sorgt dafür, dass die Inhalte von Webseiten sowohl von den Suchmaschinen als auch von den Nutzern schnell und in der jeweils optimalen Weise abgerufen werden können.
Neben den Inhalten spielt auch die Technische SEO eine entscheidende Rolle für die Platzierung in den Suchergebnissen. Die besten Inhalte nützen nichts, wenn Google sie nicht abrufen, also crawlen, und indexieren kann. Wichtig ist außerdem, dass die Inhalte schnell und optimal für jedes Gerät angezeigt werden.
Als weiterer Aspekt kommt die Datensicherheit hinzu: Wenn eine Webseite per HTTPS abgerufen werden kann, erfolgt die Übertragung der Daten verschlüsselt, so dass ein Mitlesen oder eine Manipulation der Daten durch Dritte erschwert wird.
In den folgenden Anschnitten wird beschrieben, wie man eine Webseite technisch so ausstatten kann, dass sie sowohl für Google als auch für die Nutzer gut und sicher erreichbar ist. Das kann sich in Form zufriedener Nutzer und besserer Rankings auszahlen.
Die Ladezeit von Webseiten ist ein Rankingfaktor bei Google. Wohl gemerkt nicht der Wichtigste, aber dennoch kann die Dauer bis zum vollständigen Erscheinen einer Seite im Browser den entscheidenden Ausschlag geben, ob man auf den Suchergebnisseiten vor oder hinter der Konkurrenz gelistet wird.
Google empfiehlt eine Ladezeit von maximal drei Sekunden - jede weitere Sekunde führt wahscheinlich zum Verlust von Nutzern, die sich enttäuscht abwenden und nach Alternativen suchen.
Es gibt eine große Anzahl von Faktoren, die sich auf die Ladezeit auswirken können. Nachfolgend sind einige der wichtigsten Einflussfaktoren genannt:
Die sichere Übertragung von Daten im Netz ist heute wichtiger denn je. Insbesondere dann, wenn sensitive Nutzerdaten beteiligt sind, sollte die Übertragung verschlüsselt sein. Das gilt in beide Richtungen, also sowohl vom Client zum Server als auch umgekehrt.
Die einfachste Methode zur Verschlüsselung bietet der Einsatz der Transport Layer Security (TLS). Man erkennt Webseiten mit dieser Technik am "HTTPS" in den URLs. Voraussetzung ist ein entsprechendes Server-Zertifikat. Die meisten Hosting-Anbieter haben TLS bzw. HTTPS standardmäßig im Programm, oftmals sogar ohne Mehrkosten.
Google honoriert das, denn schon lange propagiert das Unternehmen die Sicherheit vom Daten im Netz. Webseiten, die HTTPS einsetzen, können in Form besserer Rankings profitieren.
Doch nicht nur die Rankings sprechen für HTTPS: Auch moderne Browser wie Firefox oder Chrome unterstützen den Trend, indem unverschlüsselte Seiten als unsicher markiert werden. Das kann die Seitenbesucher abschrecken.
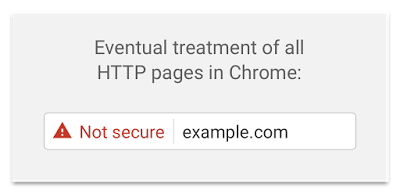
Unter Responsive Design versteht man eine Technik, die dafür sorgt, dass Webseiten sowohl auf Desktop-Rechnern, auf dem Laptop, auf Smartphones und auf Tablets optimal dargestellt werden. Das wird erreicht, indem bestimmte Elemente der Webseite ein- oder ausgeblendet, verschoben oder skaliert werden. Dadurch sind Texte auch auf kleineren Bildschirmen lesbar, Links und Buttons sind groß genug, dass sie auch mit dem Finger bedienbar sind, und Bilder passen sich dem verfügbaren Platz an.
Ein großer Vorteil von Webseiten mit Responsive Design ist, dass nur eine Variante gepflegt werden muss - im Gegensatz zu Webseiten, die über eine gesonderte Mobilvariante verfügen.
Besonders im Hinblick auf den anstehenden Wechsel auf einen neuen Google-Index ist es zu empfehlen, Webseiten auf Responsive Design umzustellen, denn zukünftig werden mobile Rankingfaktoren im Vordergrund stehen (statt wie bisher Signale der Desktop-Version).
Doch bereits heute belohnt Google Webseiten, die mobilfreundlich sind, mit besseren Rankings. Ob Google eine Webseite als mobilfreundlich einstuft oder nicht, kann man mit dem eigens dafür eingerichteten Mobile-Friendly-Test ausprobieren.
Für die meisten Content Management Systeme gibt es heute Templates, die den Anforderungen von Responsive Design entsprechen. Der Aufwand für die Umstellung hält sich also in Grenzen.
Damit eine Webseite in den Google-Ergebnissen auftauchen kann, muss Google sie crawlen und indexieren können. Beim Crawlen besucht ein sogenannter Crawler, der Googlebot, die Seiten und erfasst die dort vorhandenen Inhalte und Links. Die Links werden dann für das Crawlen weiterer Seiten genutzt. Aus diesem Grund ist eine optimierte interne Linkstruktur so wichtig.
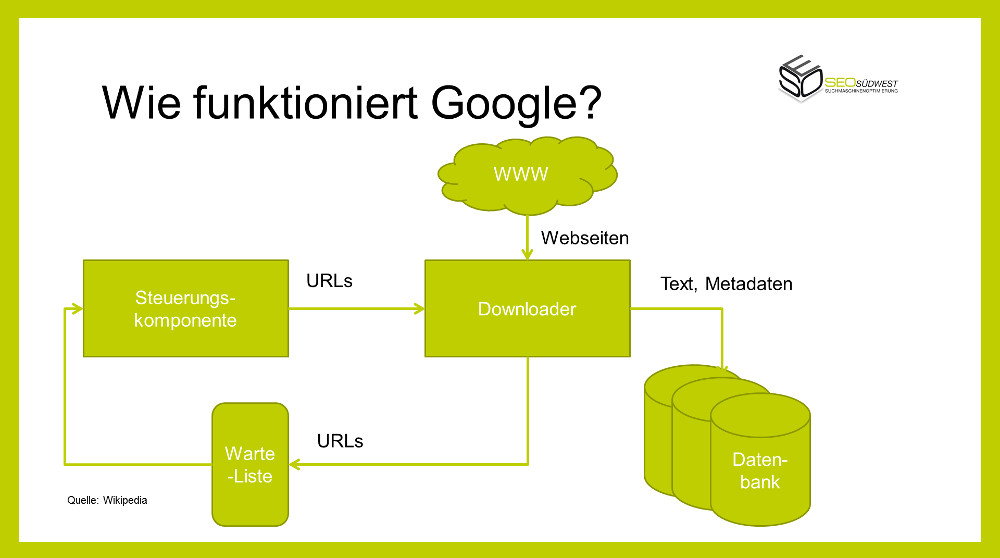
Das Indexieren ist ein darauf folgender Prozess: Google schreibt die Daten, die beim Crawlen gefunden werden, nach einer ersten Aufarbeitung in eine Art Datenbank, den Google-Index. Dieser enthält zahlreiche Felder und Kriterien, die später darüber entscheiden, ob und auf welcher Position eine Seite in den Suchergebnissen erscheinen kann.
Beim Crawlen und Indexieren kann eine Menge schief gehen - daher müssen alle Voraussetzungen so geschaffen sein, dass es möglichst wenige Barrieren für Google gibt.
Die robots.txt-Datei enthält Angaben dazu, welche Seiten und welche Ressourcen einer Webseite von den verschiedenen Crawlern abgerufen werden dürfen. Im Grunde kann man sich eine robots.txt als einfache Liste von "Du darfst"- und "Du darfst nicht"-Anweisungen vorstellen. Alles, was mit "allow" gekennzeichnet ist, darf abgerufen werden - alles, was mit "disallow" gekennzeichnet ist, ist verboten. Inhalte, die weder mit "allow" oder mit "disallow" markiert sind, dürfen ebenfalls gecrawlt werden.
Bei der Bearbeitung der robots.txt ist es wichtig, darauf zu achten, dass keine Seiten aus Versehen gesperrt werden, die eigentlich im Google-Index landen sollen. Eine Anweisung wie
disallow: /
sorgt zum Beispiel dafür, dass alle Seiten gesperrt sind.
Ebenfalls sollte man prüfen, ob alle wichtigen Ressourcen wie Bild-Ordner, JavaScript- und CSS-Verzeichnisse für die Crawler zugängig sind, denn sie werden benötigt, um eine Seite zu rendern (zu berechnen). Google ist dazu schon seit längerer Zeit in der Lage.
In der Google Search Console gibt es mehrere Möglichkeiten, dies zu prüfen: Einmal im Bereich "Crawling" unter dem Punkt "robots.txt-Tester" und im Bereich "Google-Index" unter dem Punkt "Blockierte Ressourcen".
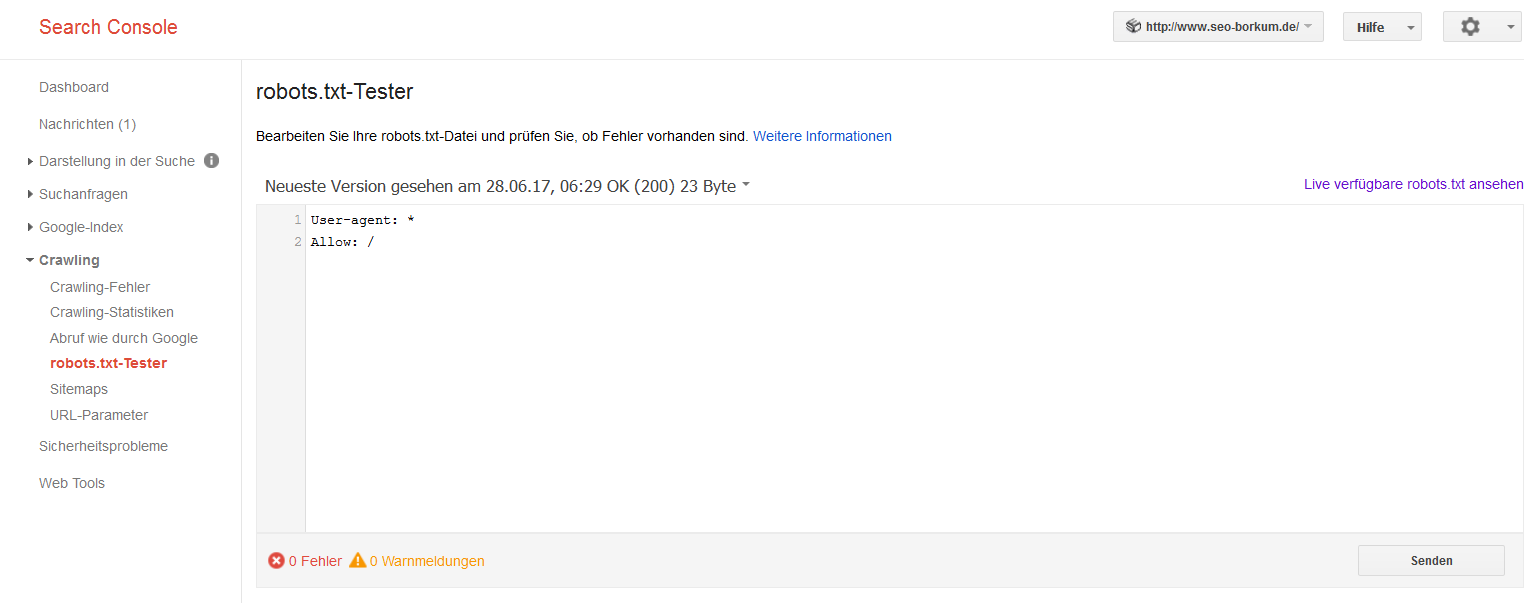
Die Meta-Robots-Anweisung steuert - anders also die robots.txt-Datei - in erster Linie nicht das Crawlen, sondern das Indexieren. Man findet die Meta-Robots im HTML-Quellcode innerhalb des <head>-Bereichs. Sie haben die folgende Form:
<meta name="robots" content="index | noindex, follow | nofollow"/>
Der erste Teil, also das "index" bzw. "noindex" teilt Google mit, ob die betreffende Seite indexiert werden soll oder nicht. Der zweite Teil, also das "follow" oder "nofollow" ist eine Anweisung, die festlegt, ob der Googlebot den auf der Seite gefundenen Links folgen soll oder nicht.
Wenn es keinen zwingenden Grund dafür gibt, eine Seite aus dem Google-Index herauszuhalten, sollte man stets "index, follow" als Wert setzen. Es kann allerdings Fälle geben, in denen es angebracht sein kann, auf "noindex" zu wechseln, etwa wenn es um Seiten geht, die für die Nutzer der Suchmaschine keinen Mehrwert bieten würden.
Wie weiter oben bereits angedeutet, kann eine gut strukturierte interne Verlinkung das Crawlen für Google erleichtern. Dabei sollte man immer von einer hierarchischen Struktur ausgehen, bei der es wenige Seiten auf der oberen Ebene und mehr Seiten auf den weiter unten angesiedelten Ebenen gibt. Beispiel: Eine Webseite verfügt über eine Startseite, von der aus man auf verschiedene Kategorien gelangt. Jede dieser Kategorien verfügt wiederum über mehrere Unterkategorien, so dass man auf dieser Ebene bereits ein Vielfaches an Seiten hat. Jede Unterkategorie besitzt eine bestimmte Anzahl von Unterseiten bzw. Landing Pages.
Durch die konsequente Verlinkung der Kategorien, Unterkategorien und Landing Pages verbessern sich die Chancen, dass Google alle Seiten erfassen und crawlen kann. Auch für die Seitenbsucher schafft eine logisch durchdachte interne Verlinkung einen besseren Überblick.
Ergänzen kann man dieses Konstrukt noch durch Querverlinkungen innerhalb einer Ebene - etwa zwischen themenverwandten Landing Pages.
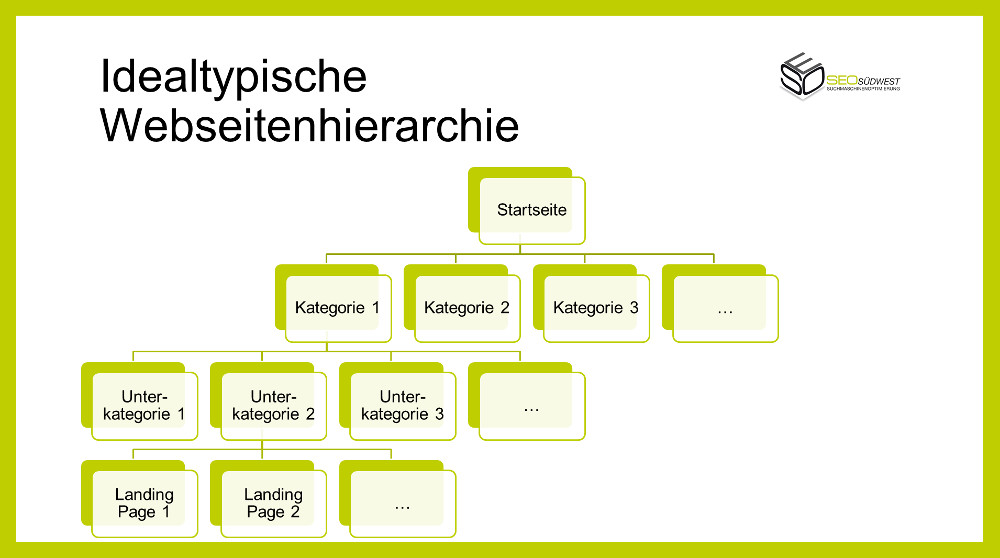
Neben einer optimierten internen Verlinkung können XML-Sitemaps eine weitere Hilfe für den Googlebot beim Crawlen sein. In diesen Dateien sind alle wichtigen URLs aufgeführt, so dass Google sie einfach nach und nach aufrufen kann.
XML-Sitemaps sollten immer auf dem aktuellen Stand sein. Wenn Seiten wegfallen, geändert oder neu angelegt werden, sollte sich dies gleich in der XML-Sitemap niederschlagen.
Es gibt übrigens verschiedene Arten von XML-Sitemaps, die man bei Google einreichen kann, unter anderem auch für Bilder, Videos oder News. Letztere sind solchen Webseiten vorbehalten, die in Googles Nachrichtensuche Google News gelistet sind.
Die meisten Content Management Systeme bieten entweder standardmäßig oder per Erweiterung die Möglichkeit, XML-Sitemaps zu erstellen.
Viel diskutiert und immer wieder einen Beitrag wert ist das sogenannte Crawl-Budget, das eine Webseite bei Google hat. Im Grunde versteht man darunter die Zahl der Seiten, die der Googlebot innerhalb einer bestimmten Zeitspanne abrufen kann oder will.
Man kann das Crawl-Budget nicht direkt beeinflussen, aber Maßnahmen dafür treffen, dass Google mehr Seiten abruft. Wichtig dazu ist vor allem eine kurze Antwortzeit des Servers, denn sobald Google erkennt, dass ein Server Probleme mit der Beantwortung von Anfragen hat, wird die Crawl-Rate reduziert.
Weitere Faktoren, die das Crawl-Budget beeinflussen:
Besondere Herausforderungen ergeben sich, wenn dynamische Webseiten und sogenannte Single Page Application gecrawlt werden sollen. Anders als herkömmliche Webseiten verhalten sich diese eher wie eine App und bestehen im Grunde nur aus einer einzigen Seite, die sich je nach Nutzerinteraktion unterschiedlich präsentiert.
Lange Zeit konnte Google mit solchen Inhalten nichts anfangen. Daher war es nötig, für die Suchmaschinen einen sogenannten "Snapshot" bereitzustellen - also ein statisches Abbild der verschiedenen Zustände, welches dann jeweils gecrawlt werden konnte.
Inzwischen kann Google JavaScript jedoch interpretieren und ausführen. Details dazu sind in diesem Artikel von Artur Kosch zu finden.
Um zu testen, wie sich eine JavaScript-basierte Webseite für den Googlebot präsentiert, kann man auf die Funktion "Abruf wie durch Google" in der Google Search Console zurückgreifen.
Zu empfehlen ist auch das SEO-Tool "Screaming Frog" - dieses beherrscht zur Zeit als eines der wenigen Werkzeuge das Interpretieren und Ausführen von JavaScript.
Redirects oder Weiterleitungen sind ein Dauerthema für SEOs. Wann werden welche Redirects benötigt, wann lässt man sie besser weg? Ein Redirect sorgt dafür, dass beim Aufruf einer URL wie zum Beispiel www.example.com/seite1.html ein Sprung auf eine andere URL stattfindet, zum Beispiel auf www.example.com/seite2.html.
Redirects sind wichtig, um Aufrufe alter Seiten oder URLs nicht zu verlieren und zum neuen Ziel zu senden. Auch bestehende Backlinks können durch den Einsatz von Redirects bewahrt werden.
Dabei ist man völlig frei in der Wahl des Weiterleitungsziels: Man kann auch auf eine komplett andere Domain verweisen.
Nachfolgend ist eine Übersicht der wichtigsten Arten von Redirects aufgeführt:
Für dauerhafte Änderungen, also zum Beispiel dann, wenn eine Webseite auf eine neue Domain umzieht, sollten 301-Redirects verwendet werden.
Bei Broken Links handelt es sich um Links, die auf nicht mehr bestehende Seiten bzw. URLs zeigen. Dabei kann es sich um interne oder externe Broken Links handeln.
Für die Besucher einer Webseite und die Suchmaschinen-Crawler sind Broken Links unschön, weil sie in eine Sackgasse führen. Aus diesem Grund sollte man die eigene Webseite regelmäßig daraufhin überprüfen, ob alle eingebundenen Links noch funktionieren. Falls Broken Links gefunden werden, sollte man diese ändern oder entfernen.
Canonical Tags und Duplicate Content stehen in einem engen Verhältnis zueinander. Duplicate Content entsteht, wenn eine Seite unter mehreren URLs verfügbar ist, zum Beispiel mit und ohne "www". Das kann dazu führen, dass Google mehrere Varianten der Seite mit verschiedenen URLs indexiert. Somit würden diese verschiedenen Varianten miteinander in Konkurrenz um die Rankings auf den Suchergebnsseiten treten, was sich negativ auswirken kann.
Als Lösung für das Problem mit Duplicate Content bieten sich die sogenannten Canonicals an: Mit ihnen lässt sich definieren, welche URL Google verwenden soll, wenn eine Seite unter verschiedenen URLs erreichbar ist. Dazu muss in jede der betroffenen Seiten ein Tag wie dieses eingebunden werden:
<link rel="canonical" href="https://example.com/hauptseite">
Google wird dann jeweils nur diese eine URL indexieren.
URLs sollten möglichst ohne zusätzliche Parameter verwendet werden, weil dadurch die Möglichkeit von Duplicate Content entsteht (siehe voriger Abschnitt). Leerzeichen und Unterstriche in URLs sind nach Möglichkeit zu vermeiden. Außerdem sollten URLs nicht zu lang sein, weil dadurch die Weiterverarbeitung und das Teilen der URLs – beispielsweise in sozialen Netzwerken – erschwert wird.
Wichtig: Ziel-Keywords, für die eine Seite ranken soll, sollten in der URL der Seite vorkommen. Das hat zwar nur eine geringe Auswirkung auf die Rankings, kann im Zweifelsfall aber dennoch von Vorteil sein. Der Aufbau der URLs sollte der Seitenhierarchie entsprechen, also die einzelnen Ebenen der Webseite abbilden.
Beispiel: www.example.com/kategorie/unterkategorie/landing-page.html
Technisch sicherlich am anspruchsvollsten und nur für technisch Fortgeschrittene zu empfehlen ist die manuelle Konfiguration des Servers, auf dem die Webseite betrieben wird.
Je nachdem, welches Hosting-Paket man gebucht hat, gibt es hier unterschiedliche Möglichkeiten. Diejenigen mit einem eigenen Server sind dabei am flexibelsten und können frei entscheiden, welche Software sie installieren. Wichtig sind das genutzte Betriebssystem auf dem Server (Windows oder Linux), die genutzte PHP-Version und die eingesetzte Datenbank.
Weitere Konfigurationsmöglichkeiten gibt es bezüglich des Cachings von Inhalten wie Bildern, JavaScript und CSS sowie der Wahl, ob die Daten vor der Übertragung komprimiert werden sollen oder nicht.
Weniger flexibel sind Hosting-Pakete, bei denen man sich einen Server mit vielen anderen Seiten teilen muss und daher weniger Einflussmöglichkeiten auf die Konfiguration hat. Dafür ist aber auch der Pflegeaufwand geringer. Für kleinere Webseiten reichen solche Pakete meist aus.
Eine Zwischenlösung stellen die "Managed Server"-Pakete dar: Hier sorgt der Hoster für bestimmte Grundaufgaben wie Updates bestehender Software. Dennoch hat der Kunde viele Möglichkeiten, das System an die eigenen Bedürfnisse anzupassen.
Technische SEO ist ein Aufgabengebiet, das für den möglichst reibungslosen, nutzerfreundlichen und sicheren Betrieb von Webseiten sorgen soll. Mit SEO haben diese Tätigkeiten nur zum Teil zu tun, denn es geht hier in erster Linie um die Nutzer. Allerdings werden Bemühungen wie der Einsatz von HTTPS und kurze Ladezeiten von Google mit vergleichsweise besseren Rankings belohnt.
Titelbild © maciek905 - Fotolia.com


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
