

Shared Hosting: IONOS blockiert Zugriffe mancher KI-Bots auf Websites
Websites, die unter Shared Hosting von IONOS laufen, sind für bestimmte KI-Bots und KI-Crawler nicht erreichbar. Das kann die Chancen auf Erwähnungen in den KI-Antworten senken.
 Gerade hat Google viele Webmaster angeschrieben und sie darauf hingewiesen, dass bestimmte Javascript- und CSS-Dateien nicht gecrawlt werden können. Als Folge droht im schlimmsten Fall eine Herabstufung des Rankings. So löst Ihr bestehende Blockaden schnell auf.
Gerade hat Google viele Webmaster angeschrieben und sie darauf hingewiesen, dass bestimmte Javascript- und CSS-Dateien nicht gecrawlt werden können. Als Folge droht im schlimmsten Fall eine Herabstufung des Rankings. So löst Ihr bestehende Blockaden schnell auf.
Vor zwei Tagen wurde berichtet, dass Google zahlreiche Webmaster wegen blockierter Javascript- und CSS-Dateien angeschrieben hat. Wenn diese Dateien nicht gecrawlt werden können, ist es für Google unter Umständen nicht möglich, die Darstellung der Webseite zu prüfen und zum Beispiel zu erkennen, ob sie mobilfreundlich ist. Als Folge von blockiertem Javascript und CSS droht im schlimmsten Fall ein schlechteres Ranking. Diese Meldung ging an die Webmaster: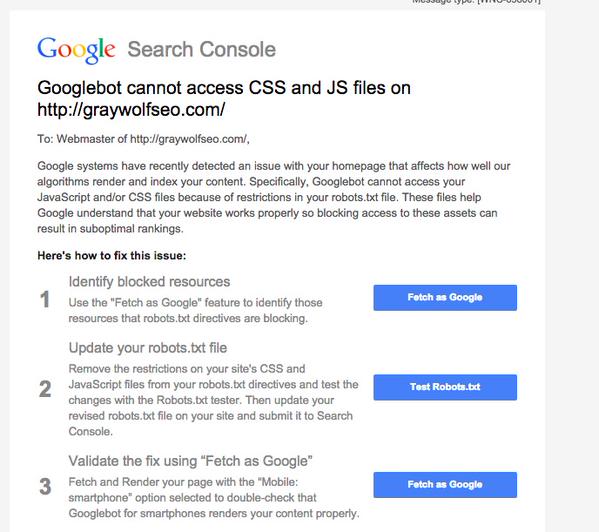
Man kann bestehende Blockaden jedoch meist schnell auflösen. Eine einfache und leicht umzusetzende Lösung hat gerade Gary Illyes von Google auf Stackoverflow vorgeschlagen. Dazu muss die robots.txt-Datei einfach die folgenden Zeilen enthalten:
User-Agent: Googlebot
Allow: .js
Allow: .css
Achtung: Ist in der robots.txt ein Verzeichnis per Disallow-Eintrag gesperrt, in dem sich Javascript oder CSS befindet, dann sticht diese Regel, weil sie spezifischer ist. Überprüft daher Eure robots.txt auf alle gesperrten Verzeichnisse, die Javascript oder CSS enthalten könnten.
In manchen Fällen liegt das Problem auch in einer falschen Konfiguration des Webservers. Wer beispielsweise den Apache-Webserver nutzt, kann das an der Konfigurationsdatei .htaccess erkennen. Dabei sollte auf ähnliche Einträge wie diesen geachtet werden:
<Files ~ "\.js$">
Header set X-Robots-Tag "noindex"
</Files>
oder
<Files ~ "\.css$">
Header set X-Robots-Tag "noindex"
</Files>
Das führt dann dazu, dass für Dateien mit der Endung ".js" oder ".css" ein HTTP-Header mitgeliefert wird, der dazu auffordert, diese Dateien nicht zu indexieren. Sofern solche Einträge vorhanden sind, sollten sie entsprechend geändert werden. Dazu am besten das "noindex" ersetzen durch "index, noarchive, nosnippet". Das führt dazu, dass die Inhalte gecrawlt werden, ohne allerdings eine Version davon im Cache abzulegen oder ein Snippet anzuzeigen.
Google schaut sich für die Prüfung auf gesperrte Dateien in der Regel nur die Homepage und die mobile Variante der Seite an, sofern es eine solche gibt. Das hat John Mueller von Google in einem Post auf Google+ erklärt:
We're primarily looking at the site's homepage & for the smartphone view of the page.
Wenn dagegen das Javascript oder das CSS von Drittanwendungen wie Social Plugins oder Diskussionsforen gesperrt sind, so stellt das in der Regel kein Problem dar. Zwar wird es auch in diesem Fall eine Warnung in der Search Console geben, doch wird in solchen Fällen nicht extra eine Nachricht an den Webmaster verschickt:
We're looking for local, embedded, blocked JS & CSS. So it would be for URLs that you can "allow" in your robots.txt, not something on other people's sites (though blocked content on other sites can cause problems too, eg, if you're using a JS framework that's hosted on a blocked URL).
Wie sich herausgestellt hat, stammen viele der wegen blockierter Ressourcen versendete Nachrichten noch aus dem April, als es im Zuge des Mobil-Friendly-Updates zu Änderungen der Rankingalgorithmen für mobile Seiten kam. Seither wird die Usability mobiler Webseiten stärker gewichtet.
Bild © AKS - Fotolia.com




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
