 Googles eigene Prozessoren, die sogenannten TPUs für Anwendungen im Bereich des maschinellen Lernens, übersteigen die Leistungsfähigkeit klassischer Prozessoren (CPUs) um ein Vielfaches. Sogar die als besonders performant eingestuften grafischen Prozessoren (GPUs) können da nicht mithalten.
Googles eigene Prozessoren, die sogenannten TPUs für Anwendungen im Bereich des maschinellen Lernens, übersteigen die Leistungsfähigkeit klassischer Prozessoren (CPUs) um ein Vielfaches. Sogar die als besonders performant eingestuften grafischen Prozessoren (GPUs) können da nicht mithalten.
Google verwendet eigens angefertigte Chips zur Beschleunigung von Anwendungen im Bereich des maschinellen Lernens. Die dafür entwickelten Chips heißen Tensor Processing Units (kurz TPUs). Tensor ist ein Begriff aus der Mathematik und kommt in der Linearen Algebra zum Einsatz. Dort beschreibt ein Tensor ein mathematisches Objekt bzw. eine Funktion, mit der mehrere Vektoren auf einen Wert abgebildet werden.
TPUs werden vor allem in Kombination mit Googles Tensor Flow-Bibliothek genutzt, die auch Ende 2015 der Öffentlichkeit zur Verfügung gestellt wurde.
Erstmals hat Google jetzt Details zu den TPUs veröffentlicht. In dem Dokument findet man unter anderem Benchmarks von TPUs mit anderen Chiparten. Demnach sind TPUs beim Einsatz für Googles Algorithmen etwa 15- bis 30mal schneller als eine herkömmliche Kombination aus CPUs und GPUs.
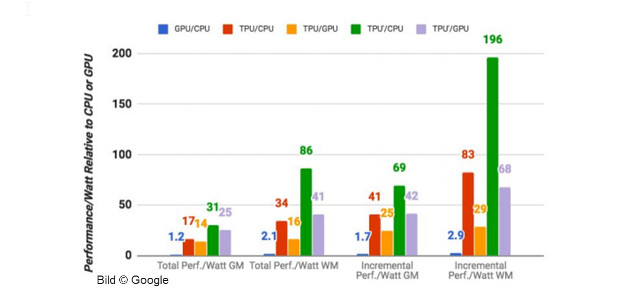
Noch beeindruckender ist die Effizienz der TPUs: Berechnet man deren Leistung im Verhältnis zum Energieverbrauch, so erreichen sie 30- bis 80mal bessere Werte (gemessen in TeraOps / Watt). Dabei hat Google die Chips auf die Anwendung im Bereich einer speziellen Art von neuronalen Netzen optimiert: den mehrschichtigen Perzeptrons. In ihnen werden die Ergebnisse innerhalb mehrerer Ebenen oder Schichten zwischen dem Eingangs- und dem Ausgangsknoten berechnet. Diese Art von neuronalen Netzen kommt in den meisten Anwendungsfällen zum Einsatz, die bei Google im Bereich des maschinellen Lernens behandelt werden.
Auch wenn Google derzeit nicht plant, die TPUs der Öffentlichkeit zur Verfügung zu stellen, so ist doch damit zu rechnen, dass andere Unternehmen die Erkenntnisse nutzen und ähnliche, vielleicht sogar noch leistungsfähigere Chips entwickeln werden.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















