 Google ist dazu übergegangen, AJAX-Seiten zu crawlen. Das Bereitstellen von HTML-Snapshots ist damit in den meisten Fällen nicht mehr notwendig.
Google ist dazu übergegangen, AJAX-Seiten zu crawlen. Das Bereitstellen von HTML-Snapshots ist damit in den meisten Fällen nicht mehr notwendig.
Google hatte im Dezember des vergangenen Jahres angekündigt, das Crawlen von Webseiten nach dem alten AJAX-Schema einzustellen. Dieses sah vor, dass ein Webserver nach dem Aufruf einer "Escaped Fragment"-URL einen statischen HTML-Snapshot für die angefragte dynamische Seite liefert. Früher war der Googlebot noch nicht fähig, JavaScript auszuführen, weshalb dieser Mechanismus notwendig wurde:
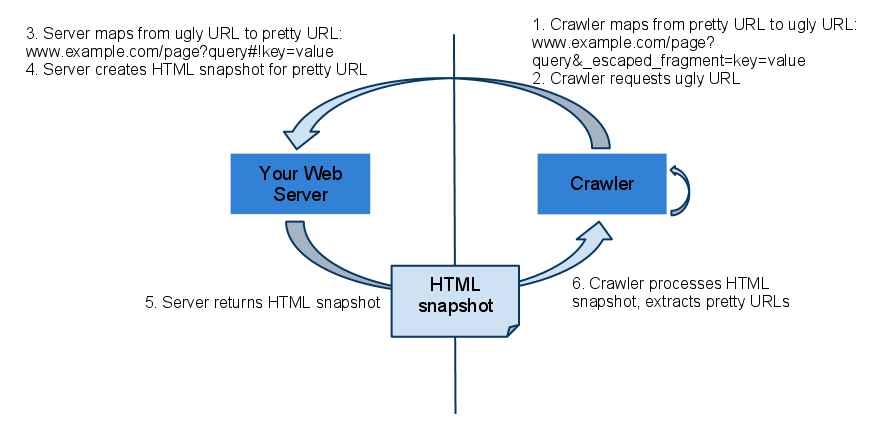
Inzwischen haben sich Googles Möglichkeiten im Umgang mit JavaScript jedoch deutlich erweitert. Daher können jetzt auch viele per JavaScript erzeugte Seiten vom Googlebot gerendert werden.
Google ist somit nicht mehr auf die Escaped Fragment-URLs angewiesen und crawlt inzwischen direkt die Hashbang-URLs, die man an der enthaltenen Zeichenkombination "#!" erkennen kann. Das bestätigte Johannes Müller per Twitter:
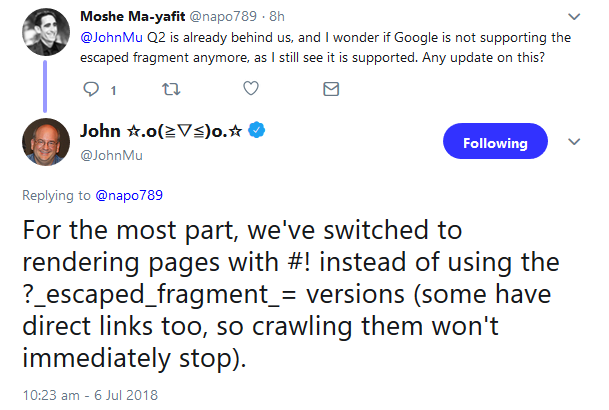
Möglich sei, laut Müller, dass noch einzelne Escaped Fragment-URLs gecrawlt würden, etwa dann, wenn diese verlinkt seien.
Titelbild © AKS - Fotolia.com
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















