 Kann Google inzwischen AJAX-Seiten crawlen, oder sind hier nach wie vor Einschränkungen zu beachten? Leider gibt es dazu keine eindeutigen Aussagen seitens des Suchmaschinenanbieters. So bleibt Webmastern und SEOs nur das Experimentieren. Alternativen für das SEO von AJAX-Seiten werden hier vorgestellt.
Kann Google inzwischen AJAX-Seiten crawlen, oder sind hier nach wie vor Einschränkungen zu beachten? Leider gibt es dazu keine eindeutigen Aussagen seitens des Suchmaschinenanbieters. So bleibt Webmastern und SEOs nur das Experimentieren. Alternativen für das SEO von AJAX-Seiten werden hier vorgestellt.
Kann Google mit AJAX-Webseiten umgehen oder nicht? Muss man immer noch zusätzliches, statisches HTML ausliefern, damit der Googlebot eine Seite crawlen kann? Derzeit stehen viele Webmaster und SEOs für dem Problem, dass es keine klaren Aussagen seitens Google darüber gibt, wie die Suchmaschine mit dynamischen Webseiten auf AJAX-Basis umgeht. Auf der einen Seite wurden die bisher geltenden Empfehlungen von Google im Herbst des vergangenen Jahres widerrufen - auf der anderen Seite fehlt es an klaren Alternativen.
Was bisher geschah
Zunächst ein kurzer Rückblick: Bis zum Oktober des letzten Jahres verlangte Google, dass AJAX-Seiten parallel zu den dynamischen Inhalten, die im Browser berechnet werden, auch jeweils ein statisches HTML-Abbild ("Snapshot") pro Unterseite bereitstellten. Die Bereitschaft zu diesem Verhalten konnte eine Webseite auf zwei Weisen signalisieren:
Verwenden von Hashbang-URLs nach dem Schema: domain.com/?query#!parameter1=wert1¶meter2=wert2
Setzen eines Meta-Tags im Head des HTML-Codes: <meta name="fragment" content="!">
Wenn Google auf eines dieser Signale stieß, wandelte es die jeweilige URL um und setzte den Parameter "_escaped_fragment_". Gemäß des obigen Beispiels würde das zur URL domain.com/?query&_escaped_fragment_=parameter1%26parameter2=key2 führen. Die Aufgabe des Servers ist es dann, für die entsprechende URL das fertige, statische HTML zu liefern, das vom Googlebot gelesen werden kann. Das verdeutlicht auch das folgende Schaubild:
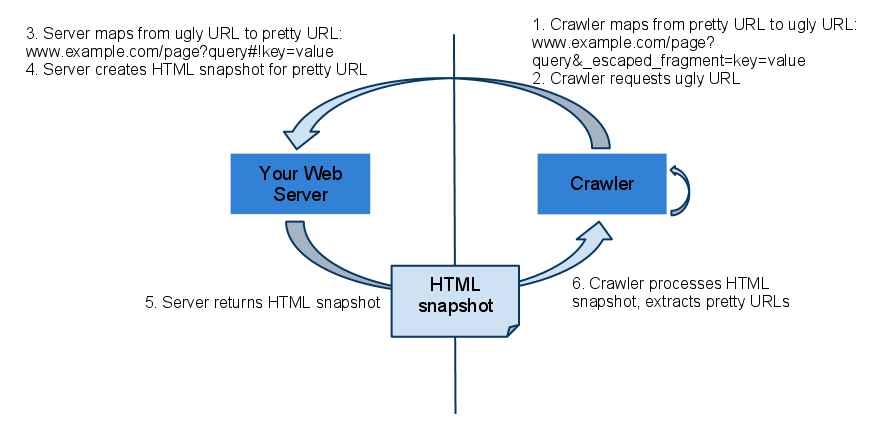
AJAX Crawling Scheme gilt nicht mehr
Seit Oktober hat diese Empfehlung jedoch keine Gültigkeit mehr und wurde von Google als "deprecated" gekennzeichnet. Das bedeutet jedoch nicht, dass dieser Mechanismus nicht mehr funktionieren würde - wer bereits eine Webseite auf Basis des AJAX Crawling Schemes erstellt hat, muss nichts ändern.
Die Frage, die sich viele Webmaster und SEOs stellen, lautet jedoch: Wie müssen neue AJAX-Webseiten gestaltet werden, damit Google sie crawlen kann? Müssen überhaupt besondere Vorkehrungen getroffen werden?
Kann Google inzwischen AJAX - oder nicht?
Leider ist das nicht ganz so einfach, wie man es sich wünschen würde. Zwar hat Google offiziell bestätigt, dass der Googlebot JavaScript versteht und damit auch Seiten auf Basis von JavaScript crawlen kann, doch gilt dies nicht ohne Einschränkungen. In manchen Fällen interpretiert Google das JavaScript nicht vollständig oder nicht korrekt. Zudem crawlt Google keine AJAX-Links, die erst durch den Nutzer aktiviert werden müssen.
Eine weitere Schwierigkeit kommt bei vielen AJAX-Webseiten dazu: Das verwendete URL-Schema kann dem Crawlen und Indexieren entgegenstehen. Viele AJAX-Seiten verwenden URL-Fragmente, die durch ein "#" vom Rest der URL abgetrennt sind. Beispiel: domain.com/#shop&category=foo. Tests mit entsprechenden URLs in der Google Search Console ("Abruf wie durch Google") zeigen, dass URL-Fragmente ignoriert werden. Johannes Müller von Google hat vor wenigen Tagen auf Anfrage bestätigt, dass Google noch Probleme mit solchen URLs hat:
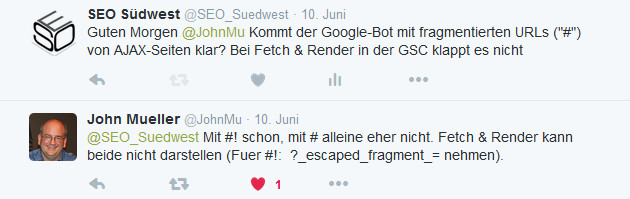
Was kann also konkret getan werden, damit Google eine AJAX-Seite versteht und möglichst vollständig und korrekt indexiert? Hier gibt es mehrere Alternativen, die einen unterschiedlich hohen Aufwand mit sich bringen. Empfehlungen dazu können auch nur unter Vorbehalt ausgesprochen werden, weil es tatsächlich auf den Einzelfall anzukommen scheint, ob eine Lösung funktioniert oder nicht.
Es empfiehlt sich daher, zunächst eine Testseite als Modell anzulegen und diese in der Google Search Console anzumelden. Somit ist man in der Lage, die Funktion "Abruf wie durch Google" zu verwenden und zu sehen, ob die Seite wie gewünscht von Google gerendert werden kann.
Alternative 1: Hashbang-URLs ohne _escaped_fragment_
Google gibt an, inzwischen JavaScript interpretieren zu können. Laut einer FAQ-Seite crawlt, rendert und indexiert Google inzwischen direkt die #!-URLs. Daher wäre es einen Versuch wert, dies in der Praxis zu testen. Im Erfolgsfall müssten die Seiten auch ohne das statische HTML im Index landen, das normalerweise per _escaped_fragment_ ausgeliefert wird.
Alternative 2: pushState() verwenden
Mittels pushState() lassen sich URLs in der Browser-Historie beliebig verändern. Statt der URL-Fragmente können so ganz "normale" URLs gesetzt werden. Das hat zwei Vorteile: Für die Nutzer ergibt sich ein übersichtlicheres Bild, und für die Crawler besteht die Chance, die Inhalte der Webseite zu erfassen. Dazu ist es aber sehr wahrscheinlich notwendig, dass der Server beim Abruf einer manipulierten URL ein für den Crawler lesbares HTML ausliefert.
Bei der Verwendung von pushState() sind einige Dinge zu beachten. So unterstützen beispielsweise nur moderne Browser diese Funktion. Ältere Browser wie der IE8 sind dagegen ausgeschlossen. Zudem muss man den Fall berücksichtigen, in dem ein Nutzer den Zurück-Button des Browsers nutzt. Dieses Ereignis muss per popState() abgefangen werden, damit es zu keinem Fehler kommt.
Alternative 3: Progressive Enhancement
Die sicherlich sauberste, aber auch aufwändigste Lösung besteht darin, sich bei der Entwicklung einer Webseite am Grundsatz des Progressive Enhancements zu orientieren. Auch Google empfiehlt diese Vorgehensweise. Progressive Enhancement bedeutet, dass die wichtigsten Inhalte einer Webseite für ein möglichst breites Spektrum an Nutzern und Clients verfügbar sind - also zum Beispiel für ältere Browser, Bildschirmleseprogramme und mobile Clients - und natürlich auch für die Crawler der Suchmaschinen. Man erstellt dabei zunächst das HTML-Grundgerüst, das später um Zusatzfunktionen und spezielles Layout erweitert wird. Leistungsfähigere Browser erhalten zusätzliche Funktionen.
Ein Kernbestandteil des Progressive Enhancements ist die richtige Verlinkung. Dabei werden AJAX- und statische Links parallel angeboten. Mit Hilfe einer Technik, die Hijax genannt wird, kann gewährleistet werden, dass jeweils immer der richtige Link verwendet wird - je nach Fähigkeiten des Clients. Ein Beispiel:
<a href="/ajax.htm?foo=32" onClick="navigate('ajax.html#foo=32');
return false">foo 32</a>
Im Falle eines JavaScriptfähigen Browsers würde der Link "axax.html#foo=32" aufgerufen werden. Alle anderen folgen dem Link "ajax.htm?foo=32".
Grundsätzliche Empfehlungen für Seiten mit JavaScript
Egal, für welche Alternative man sich entscheidet: Die Ressourcen, die eine auf JavaScript basierende Webseite benötigt, müssen für den Crawler verfügbar sein. Ein Sperren entsprechender Dateien per robots.txt muss also auf jeden Fall vermieden werden. Auch sollte beachtet werden, dass die Zahl der Ressourcen begrenzt bleibt. Wenn zu viele Dateien nachgeladen werden müssen und es zu Timeouts kommt, kann der Crawler die Seite möglicherweise nicht korrekt rendern. Weitere Tipps für das SEO von JavaScript-Seiten gibt es hier.
Schlussfolgerungen
Keiner kann momentan so genau sagen, was der Googlebot kann und wo die Grenzen liegen. Es bleiben also nur individuelle Experimente. Am besten sollte man frühzeitig eine Testseite anlegen und diese in der Google Search Console anmelden. Damit lässt sich abschätzen, ob Google mit der genutzten Systematik klarkommt. Gerade bei der Erstellung neuer Seiten sollte man die Crawlbarkeit stets im Hinterkopf behalten und Alternativen anbieten.
Titelbild © makc76 - Fotolia.com
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















