Google kündigt großes Core-Update für heute an
![]() Google hat für den heutigen Tagesverlauf ein großes Core-Update angekündigt. Das Update kommt nicht komplett überraschend - es war zu erwarten.
Google hat für den heutigen Tagesverlauf ein großes Core-Update angekündigt. Das Update kommt nicht komplett überraschend - es war zu erwarten.



Google: 'Niemand bei uns zählt die Wörter auf einer Webseite'
 Schon öfter hat Google erklärt, die Wortanzahl spiele keine Rolle für die Rankings. Laut einer aktuellen Aussage von Johannes Müller wird die Wortanzahl von Google überhaupt nicht beachtet.
Schon öfter hat Google erklärt, die Wortanzahl spiele keine Rolle für die Rankings. Laut einer aktuellen Aussage von Johannes Müller wird die Wortanzahl von Google überhaupt nicht beachtet.
Google bietet jetzt auch die Optimierung von Ladenbesuchen als Ziel für Smart Bidding-Kampagnen
 Smart Bidding-Kampagnen in Google Ads können jetzt auch zur Optimierung der Anzahl von Ladenbesuchen genutzt werden.
Smart Bidding-Kampagnen in Google Ads können jetzt auch zur Optimierung der Anzahl von Ladenbesuchen genutzt werden.
SEO-Recap vom 23.09.: endlich aktuellere Daten für die Google Search Console
 Google stellt jetzt in der Search Console Leistungsdaten bereits nach einem Tag zur Verfügung.
Google stellt jetzt in der Search Console Leistungsdaten bereits nach einem Tag zur Verfügung.
Google Search Console zeigt jetzt Daten bereits nach einem Tag an
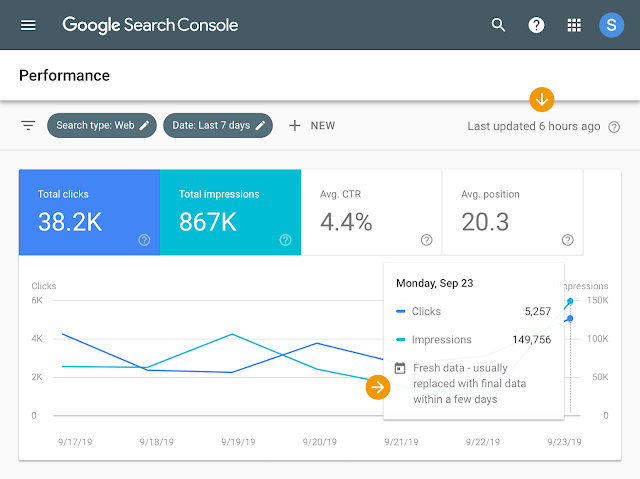 Eine gute Nachricht für viele Webmaster: Google stellt die Leistungsdaten in der Search Console jetzt bereits nach einem Tag zur Verfügung.
Eine gute Nachricht für viele Webmaster: Google stellt die Leistungsdaten in der Search Console jetzt bereits nach einem Tag zur Verfügung.
Google: Datum in der URL ist kein Problem
 Durch das Verwenden des Datums innerhalb von URLs sind laut Google keine negativen Auswirkungen auf die Rankings zu erwarten.
Durch das Verwenden des Datums innerhalb von URLs sind laut Google keine negativen Auswirkungen auf die Rankings zu erwarten.
YouTube macht Rückzieher: Channels können Verifizierungsabzeichen behalten
 YouTube beugt sich dem Protest vieler Nutzer und wird nun doch keine bereits vergebenen Verifizierungsabzeichen entziehen. Ursprünglich war vorgesehen gewesen, dass zumindest einige Channels ihr Abzeichen aufgrund geänderter Verifizierungsanforderungen verlieren sollten.
YouTube beugt sich dem Protest vieler Nutzer und wird nun doch keine bereits vergebenen Verifizierungsabzeichen entziehen. Ursprünglich war vorgesehen gewesen, dass zumindest einige Channels ihr Abzeichen aufgrund geänderter Verifizierungsanforderungen verlieren sollten.
Google erklärt Ranking von Original-Inhalten
![]() Google verwendet unterschiedliche Signale, um Original-Inhalte zu erkennen. Inhalte hinter einer Paywall haben die gleichen Rankingchancen wie frei verfügbare Inhalte.
Google verwendet unterschiedliche Signale, um Original-Inhalte zu erkennen. Inhalte hinter einer Paywall haben die gleichen Rankingchancen wie frei verfügbare Inhalte.
ANZEIGEN

Google: Backlinks von IP-Adressen sind kein Problem
 Links von der genutzten IP-Adresse zur eigenen Website sind für Google kein Problem. Das gilt auch für Links von IPs insgesamt. Allerdings empfiehlt Google, für eine Zuordnung von IP zu Hostnamen zu sorgen.
Links von der genutzten IP-Adresse zur eigenen Website sind für Google kein Problem. Das gilt auch für Links von IPs insgesamt. Allerdings empfiehlt Google, für eine Zuordnung von IP zu Hostnamen zu sorgen.
Google: Downloadzeit von 400 bis 600 Millisekunden pro Seite ist zu lang
 Das Herunterladen einer Webseite sollte laut Google weniger als 400 bis 600 Millisekunden betragen. Ansonsten besteht die Gefahr, dass Google weniger Seiten crawlt.
Das Herunterladen einer Webseite sollte laut Google weniger als 400 bis 600 Millisekunden betragen. Ansonsten besteht die Gefahr, dass Google weniger Seiten crawlt.