Google: Gruppierung der Seiten für Core Web Vitals hängt vom Traffic ab
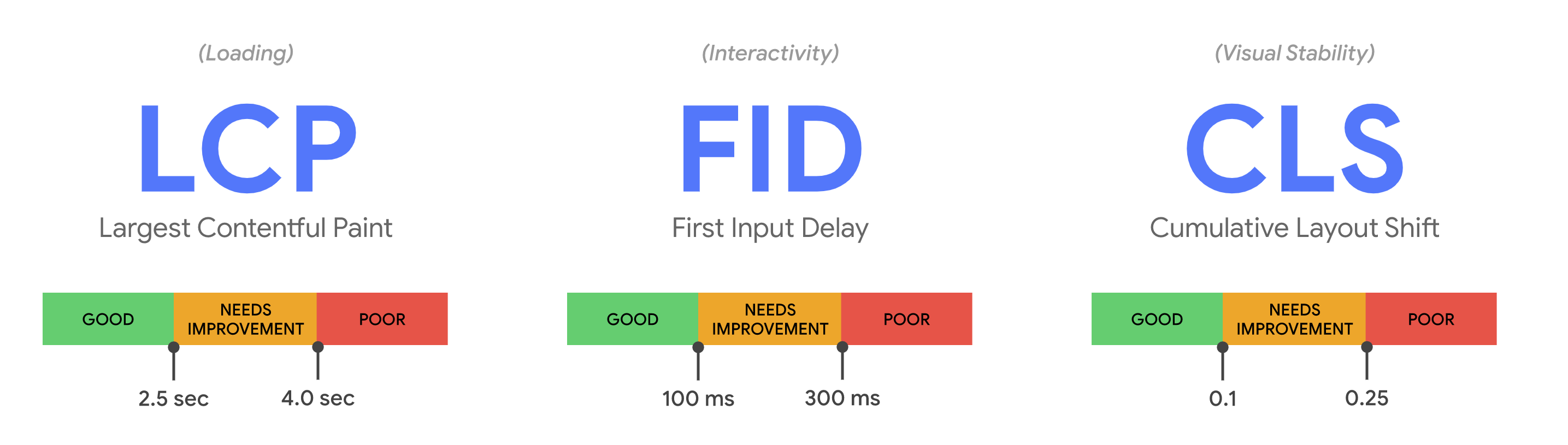 Welche Gruppierung Google bei den Seiten einer Website für die Core Web Vitals vornimmt, hängt von den verfügbaren Daten und damit vom Traffic der Seiten ab.
Welche Gruppierung Google bei den Seiten einer Website für die Core Web Vitals vornimmt, hängt von den verfügbaren Daten und damit vom Traffic der Seiten ab.



Warum 404-Fehler in der Google Search Console eine gute Nachricht sein können
 404-Fehler in der Google Search Console können ein Hinweis darauf sein, dass Google alle wichtigen URLs einer Website gecrawlt hat.
404-Fehler in der Google Search Console können ein Hinweis darauf sein, dass Google alle wichtigen URLs einer Website gecrawlt hat.
Google: Klickwahrscheinlichkeit spielt bei der Gewichtung von Links keine Rolle
 Die Wahrscheinlichkeit, dass jemand auf einen Link klickt, sowie der Traffic, der über einen Link gesendet wird, spielen für Google bei der Gewichtung von Links keine Rolle.
Die Wahrscheinlichkeit, dass jemand auf einen Link klickt, sowie der Traffic, der über einen Link gesendet wird, spielen für Google bei der Gewichtung von Links keine Rolle.
Google: Weiteres Title Update sorgt für vermehrte Nutzung der Title Tags: statt 80 jetzt 87 Prozent
![]() Google hat die Erstellung der Titel für die Suchergebnisse erneut angepasst und verwendet nach eigenen Aussagen jetzt häufiger die Angaben aus den Title Tags.
Google hat die Erstellung der Titel für die Suchergebnisse erneut angepasst und verwendet nach eigenen Aussagen jetzt häufiger die Angaben aus den Title Tags.
Plötzlicher Rankingverlust für ein wichtiges Keyword: Das kann an unklarem Search Intent liegen
 Wenn eine Website für ein wichtiges Keyword in der Suche plötzlich abstürzt, kann es daran liegen, dass Google die Suche-Intention der Landing Page nicht richtig zuordnen kann.
Wenn eine Website für ein wichtiges Keyword in der Suche plötzlich abstürzt, kann es daran liegen, dass Google die Suche-Intention der Landing Page nicht richtig zuordnen kann.
Google: Es gibt keine Möglichkeit, Sitelinks zu blockieren
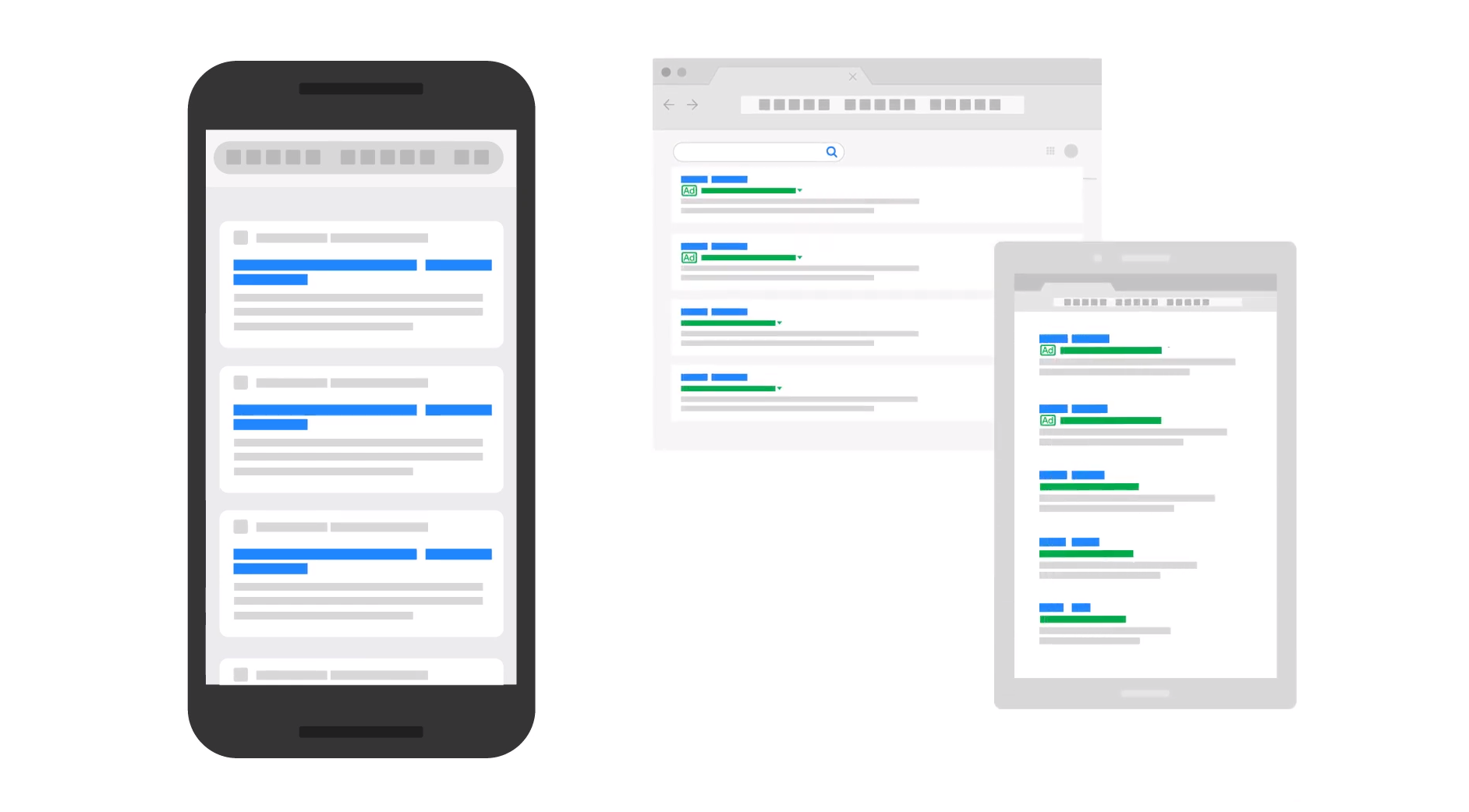 Es ist nicht möglich, bestimmte Sitelinks von der Darstellung in den Suchergebnissen von Google auszuschließen. Einzig die Verwendung von 'noindex' würde helfen.
Es ist nicht möglich, bestimmte Sitelinks von der Darstellung in den Suchergebnissen von Google auszuschließen. Einzig die Verwendung von 'noindex' würde helfen.
Google zur Frage, ob das Verbergen des Autoren aus Sicherheitsgründen schlecht für EAT ist
 Es kann gute Gründe geben, den Namen des Autoren oder der Autorin auf einer Website nicht zu nennen. Wie geht Google damit um, und hat es Auswirkungen auf EAT?
Es kann gute Gründe geben, den Namen des Autoren oder der Autorin auf einer Website nicht zu nennen. Wie geht Google damit um, und hat es Auswirkungen auf EAT?
Google ruft robots.txt nicht bei jedem Crawl ab
 Google ruft die robots.txt nicht bei jedem Crawl ab, sondern nutzt auch eine im Cache abgelegte Version der Datei. Das passiert etwa einmal pro Tag.
Google ruft die robots.txt nicht bei jedem Crawl ab, sondern nutzt auch eine im Cache abgelegte Version der Datei. Das passiert etwa einmal pro Tag.
ANZEIGEN

Ja, Google kann beim Crawlen automatisch Formulare ausfüllen
 Google füllt in einzelnen Fällen Formulare aus, wenn der Googlebot darauf stößt. Das kann zum Beispiel dazu führen, dass interne Suchergebnisseiten indexiert werden.
Google füllt in einzelnen Fällen Formulare aus, wenn der Googlebot darauf stößt. Das kann zum Beispiel dazu führen, dass interne Suchergebnisseiten indexiert werden.
Google: 'Noindex' für syndizierte Inhalte bietet keine Gewähr, dass das Original in der Suche erscheint
 Das Setzen eines 'noindex' für syndizierte Inhalte bietet keine Sicherheit, dass statt der Kopien das Original in der Suche angezeigt wird. Das gilt auch für Google Discover.
Das Setzen eines 'noindex' für syndizierte Inhalte bietet keine Sicherheit, dass statt der Kopien das Original in der Suche angezeigt wird. Das gilt auch für Google Discover.