Google nutzt dieselben Algorithmen für die Top-10 wie für die Top-100
 Die besten zehn Suchergebnisse von Google werden durch dieselben Algorithmen bestimmt wie die dahinter folgenden Ergebnisse.
Die besten zehn Suchergebnisse von Google werden durch dieselben Algorithmen bestimmt wie die dahinter folgenden Ergebnisse.
- Erstellt am .
Die besten zehn Suchergebnisse von Google werden durch dieselben Algorithmen bestimmt wie die dahinter folgenden Ergebnisse.
 Wozu sollte man noch die Titel einer Webseite optimieren, wenn Google diese ohnehin ändert? Immerhin hat Google einen guten Grund, das zu tun.
Wozu sollte man noch die Titel einer Webseite optimieren, wenn Google diese ohnehin ändert? Immerhin hat Google einen guten Grund, das zu tun.
 Anzeigen sind laut Google oftnals die relevanteren Suchergebnisse. Welche Arten von Suchergebnissen Google anzeigt, hängt von einem speziellen Verfahren ab, bei dem verschiedene Rankingfaktoren miteinander konkurrieren. Und: Es besteht wahrscheinlich keine Abhängigkeit zwischen bezahlten Sucheanzeigen und organischen Ergebnissen.
Anzeigen sind laut Google oftnals die relevanteren Suchergebnisse. Welche Arten von Suchergebnissen Google anzeigt, hängt von einem speziellen Verfahren ab, bei dem verschiedene Rankingfaktoren miteinander konkurrieren. Und: Es besteht wahrscheinlich keine Abhängigkeit zwischen bezahlten Sucheanzeigen und organischen Ergebnissen.
 Google zeigt in bestimmten Fällen auch Suchergebnisse an, die das gesuchte Keyword nicht enthalten. Das zeigt ein aktuelles Beispiel.
Google zeigt in bestimmten Fällen auch Suchergebnisse an, die das gesuchte Keyword nicht enthalten. Das zeigt ein aktuelles Beispiel.
 Bei der Analyse der Google-Ergebnisse sollte man sich nicht auf alte Dokumentationen und wissenschaftliche Arbeiten über Algorithmen verlassen. Das hat Johannes Müller von Google jetzt angemerkt.
Bei der Analyse der Google-Ergebnisse sollte man sich nicht auf alte Dokumentationen und wissenschaftliche Arbeiten über Algorithmen verlassen. Das hat Johannes Müller von Google jetzt angemerkt.
 Google soll für die Bewertung von Webseiten auf Techniken der Sentimentanalyse zurückgreifen. Stimmungen und Empfindungen gegenüber einer Marke oder einer Webseite, die zum Beispiel in sozialen Netzwerken geäußert werden, könnten damit Einfluss auf die Rankings nehmen.
Google soll für die Bewertung von Webseiten auf Techniken der Sentimentanalyse zurückgreifen. Stimmungen und Empfindungen gegenüber einer Marke oder einer Webseite, die zum Beispiel in sozialen Netzwerken geäußert werden, könnten damit Einfluss auf die Rankings nehmen.
 Es gibt einen Zusammenhang zwischen der Ladezeit einer Webseite und der Crawling-Aktivität von Google. Das zeigt auch ein aktuelles Beispiel.
Es gibt einen Zusammenhang zwischen der Ladezeit einer Webseite und der Crawling-Aktivität von Google. Das zeigt auch ein aktuelles Beispiel.
 Das Crawlen von 404- und 410-Fehlerseiten belastet das Crawl-Budget. Damit wird eine frühere Aussage seitens Google präzisiert.
Das Crawlen von 404- und 410-Fehlerseiten belastet das Crawl-Budget. Damit wird eine frühere Aussage seitens Google präzisiert.
 Wer wissen möchte, wie Google mit Duplicate Content umgeht, wird die heutigen Äußerungen von Gary Illyes sehr interessant finden. Bemerkenswert ist dabei vor allem, dass die Behandlung von Duplicate Content in mehreren Phasen stattfindet.
Wer wissen möchte, wie Google mit Duplicate Content umgeht, wird die heutigen Äußerungen von Gary Illyes sehr interessant finden. Bemerkenswert ist dabei vor allem, dass die Behandlung von Duplicate Content in mehreren Phasen stattfindet.
Google zeigt je nach Nutzer unterschiedliche Suchergebnisse an. Bei der Personalisierung der Suchergebnisse wird eine Reihe von Faktoren einbezogen. Welche das sein könnten, zeigt ein Patent, das Google gerade aktualisiert hat.
Google erkennt zwar in manchen Fällen dynamisch per JavaScript gesetzte Meta-Tags; es gibt aber Ausnahmen, die man kennen sollte.
 Google rät davon ab, Redirects in Abhängigkeit des Ortes durchzuführen, von dem die IP-Adresse des Besuchers stammt. Das kann zu Problemen bei der Nutzung und bei der Indexierung der Seiten führen.
Google rät davon ab, Redirects in Abhängigkeit des Ortes durchzuführen, von dem die IP-Adresse des Besuchers stammt. Das kann zu Problemen bei der Nutzung und bei der Indexierung der Seiten führen.
Das Zusammenfügen von Inhalten anderer Seiten auf einer Webseite, das sogenannte Content Stitching, fällt laut Google nicht unter den Begriff des Near Duplicate Contents. Dennoch sollte man diese Technik nicht anwenden, denn es ist ziemlich sicher, dass Google dies erkennen kann.
 Bindestriche können je nachdem, wie sie verwendet werden, die Bedeutung von Suchanfragen verändern und damit zu völlig unterschiedlichen Suchergebnissen führen.
Bindestriche können je nachdem, wie sie verwendet werden, die Bedeutung von Suchanfragen verändern und damit zu völlig unterschiedlichen Suchergebnissen führen.
Wenn Google bereits gefundene 404-Seiten erneut besucht, geht das nicht zu Lasten des Crawl-Budgets. Das liegt an der Reihenfolge, die Google beim Crawlen einhält.
Noch immer ist ein großer Antei der täglich bei Google anfallenden Suchanfragen komplett neu. 15 Prozent der Suchanfragen wurden so in der Vergangenheit noch nicht gestellt. Und dieser Anteil könnte sogar noch steigen.
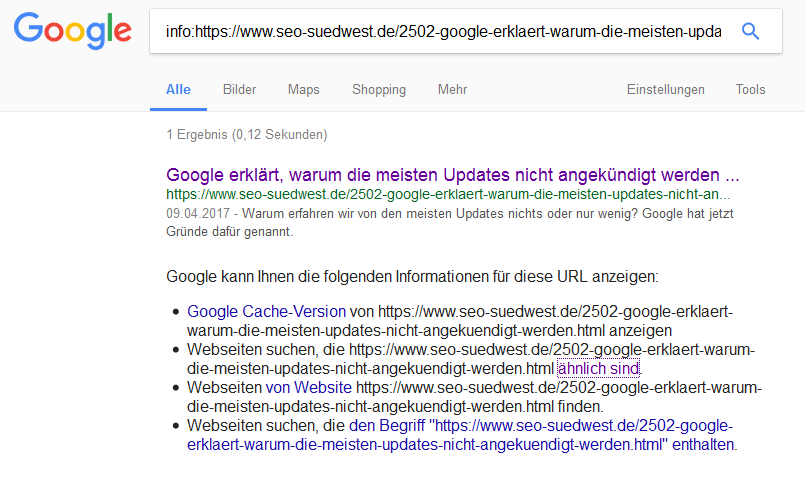 Wenn man wissen möchte, welche von mehreren möglichen URLs von Google indexiert wurde, kann man den "info:"-Sucheoperator verwenden.
Wenn man wissen möchte, welche von mehreren möglichen URLs von Google indexiert wurde, kann man den "info:"-Sucheoperator verwenden.
 Zwei Google-Mitarbeiter haben sich dazu geäußert, wie Google mit unterschiedlichen Arten von "und" umgeht. Interessant ist dabei vor allem, dass sich die beiden Antworten unterscheiden.
Zwei Google-Mitarbeiter haben sich dazu geäußert, wie Google mit unterschiedlichen Arten von "und" umgeht. Interessant ist dabei vor allem, dass sich die beiden Antworten unterscheiden.
 Google hat mit Hilfe von Bewegungsdaten seiner Nutzer bereits etwa vier Milliarden Besuche in lokalen Läden und Geschäften erfasst, die nach dem Klick auf eine Anzeige erfolgt sind. Diese Daten sollen bald vielen weiteren AdWords-Kunden zugute kommen.
Google hat mit Hilfe von Bewegungsdaten seiner Nutzer bereits etwa vier Milliarden Besuche in lokalen Läden und Geschäften erfasst, die nach dem Klick auf eine Anzeige erfolgt sind. Diese Daten sollen bald vielen weiteren AdWords-Kunden zugute kommen.
 Demnächst könnten sprachbezogene Suchanfragen (Voice Search) gesondert in der Google Search Console ausgewiesen werden. Laut Google stehen die Daten bereits zur Verfügung, sie werden aber bisher noch nicht angezeigt.
Demnächst könnten sprachbezogene Suchanfragen (Voice Search) gesondert in der Google Search Console ausgewiesen werden. Laut Google stehen die Daten bereits zur Verfügung, sie werden aber bisher noch nicht angezeigt.